Что такое веб-архив и как им пользоваться
Содержание:
- Что такое веб-архив
- Wayback Machine Browser Extension
- Возможности использования веб-архивов
- The Ghosts of Pages Past 1: Why Might You Use Wayback Machine?
- Celebrate the Internet Archive’s 25th Anniversary!
- Что такое «Веб Архив»?
- История создания Internet Archive
- Как пользоваться веб-архивом?
- Проекты, предоставляющие историю сайта
- Принцип работы веб-архива
- «Archivarix» — оптимальный инструмент для новичков и профессионалов
- But What if a Page I want to See is not in the Archive?
- Цензура и другие угрозы
- Качаем сайт с web.archive.org
- web.archive.org
- Как использовать веб-архив?
- Восстановление сайта из веб архива
Что такое веб-архив
Веб-архив сайтов позиционируется как своеобразная бесплатная машина времени, позволяющая вернуться на месяцы или годы назад, чтобы увидеть, как выглядел ресурс на тот момент. При этом у каждого сайта сохраняются многочисленные версии от разных дат, которые зависят от посещений проекта краулерами веб-архива. У популярных сайтов может сохраняться тысячи версий, которые обновлялись ежедневно множество раз на протяжении всего периода существования проекта:
Веб-архив основан в начале 1996 года и с этого времени в нем сохранено более 330 миллиардов веб-страниц, включая 20 миллионов книг, 4,5 миллионов аудиофайлов и 4 миллиона видео, занимающие свыше тысячи терабайт. Ежедневно сайт посещают миллионы пользователей, и он входит в ТОП-300 самых популярных проектов мира.
Wayback Machine Browser Extension
The Wayback Machine also has an official browser extension for Google Chrome. Using it to archive web pages is super easy. Simply navigate to a page you want to archive, click on the Wayback Machine icon in your toolbar and click “Save Page Now.”
In addition to making it even easier to save pages, the browser extension has another nifty trick up ts sleeve. Have you ever clicked on a link only to be confronted by a vague 404 error message? Whether it is a valuable source for your research paper or a really good recipe, it can be incredibly frustrating. With the Wayback Machine extension installed, that frustration could turn into a sigh of relief. When your browser runs into a dead end, the extension will search the archive to see if there is a saved copy on the Wayback Machine. If there is, it will ask you if you would like to visit that page.
If you don’t use Chrome, don’t fret. There is a Wayback Machine extension available for Firefox; however, it is still a work in progress. Additionally, there are plans to develop an extension for Safari users as well.
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
The Ghosts of Pages Past 1: Why Might You Use Wayback Machine?
What we’re gonna do right here is go back, way back, back into time.
Looking at Site Changes
The first reason you’d use Wayback Machine is to look at old versions of pages within a site.
This is useful for several reasons.
- You may have deleted a page accidentally from your site and need to reinstate it but don’t have a backup. You can possibly use Wayback Machine to recreate your lost page… if it is in the archive!
- If you’ve seen a visitor decrease to certain pages you might check to see if it’s because you changed something. You could use the Archive to look at the page and compare it to the current version.
- You might need proof that a detrimental change made in the past had nothing to do with you. Wayback Machine could prove that the change was made prior to you having access to the site.
- Wayback Machine could demonstrate your link building activities to clients. You could use it to show archived pages on sites where your inbound links appear after a certain date.
Looking at robots.txt
The Wayback Machine doesn’t only crawl and archive web pages as you can see in the pie chart above. It will also archive other file types on your domain such as your robots.txt file.
Looking at an archived version of robots.txt might give you pointers if you are having search engine crawlability problems. You could look at a past version of it to determine if any change you made caused the issues.
Checking for Intellectual Property Infringements
Let’s say you’ve seen that someone has been blatantly and illegally trading off your protected trademarks. Or maybe they’ve plagiarised your valuable intellectual property.
You may have sent a cease and desist asking the offenders to remove your intellectual property from their site.
The guilty party may have ignored your legal threats completely, so you decide upon the potentially costly path of litigation.
Your lawyer sets things in motion and all of a sudden your intellectual property disappears from the offending site to “bury the evidence”.
Wayback Machine might be able to show snapshots of the pages on their site where the infringement was committed. This would prove beyond dispute that you have been wronged.
Looking at How a Site Has Changed Over Time
If you take on a new client and want to understand how their website has evolved, Wayback Machine might be the perfect place to provide an overview.
The archive could show you technical changes made or even tell you a story of how the company has developed.
You could even use Wayback Machine in your preparation to pitch to a new client for their business. This might help you demonstrate a deeper appreciation of their story than your competitors who are also pitching.
Looking for Changed URL Structures
The URL structures for a site you manage for a client changed a while back. The organic traffic to the site fell sharply as a result. These changes weren’t documented and so nobody knows how to revert them.
In this scenario you might be able to use the archive to check URL structures and either reinstate them or set up redirections correctly.
N.B. If you’ve noticed decreased visits in Google Analytics, you can identify your historical URL structures there too.
Looking at the Historical Information Architecture of the Site
The archive might be able to show you how a website was organised in terms of the page or category hierarchy. It could even demonstrate the previous navigation structure.
This could be extremely useful when trying to understand whether categories or pages have been merged at some point. Equally it could present you with a better understanding of how past navigation structures have impacted conversion rates.
Celebrate the Internet Archive’s 25th Anniversary!
As the Internet Archive turns 25, we invite you on a journey from way back to way forward, through the pivotal moments when knowledge became more accessible for all. On this anniversary page you can:
- sign up for our virtual celebration
- create a video anniversary message
- tweet about how the Internet Archive has enhanced your life & work
- dive deep into our stories, collections & important milestones in an interactive timeline
- send us a donation for our birthday!
But first, in the video above, go way back to 1996 when a young computer scientist named Brewster Kahle dreamed of building a “Library of Everything” for the digital age. A library containing all the published works of humankind, free to the public, built to last the ages. He named this digital library the Internet Archive. Its mission: to provide everyone with “Universal Access to All Knowledge.”
Что такое «Веб Архив»?
Перед тем, как преступить к обзору сервиса «Archivarix», следует вкратце ознакомиться с так называемым «Веб Архивом», дабы понять что он собой представляет. Итак, «Веб Архив» (официально — Интернет Архив) представляет собой организацию некоммерческого типа, которая ведет свою деятельность с 1996 года.
Данная организация занимается сбором копий интерне-страниц, включая размещенный на них контент:
- статьи;
- фотографии;
- изображения (в том числе анимацию);
- видео и аудио;
- программное обеспечение;
- а также иную информацию.
А общий размер базы составляет (по состоянию на 2019 год) около 45 петабайт, при этом количество сохраненных копий веб-страниц достигло рекордной и беспрецедентной отметки в 502 млрд!
В отличие от кеша поисковых систем (который так же содержит сохраненные копии веб-ресурсов), «Веб Архив» обеспечивает долгосрочное хранение файлов и информации, а также имеет юридический статус библиотеки (с 2007 года).
История создания Internet Archive
В 1996 году Брюстер Кайл, американский программист, создал Архив Интернета, где он начал собирать копии веб-сайтов, со всей находящейся в них информацией. Это были полностью сохраненные в реальном виде страницы, как если бы вы открыли необходимый сайт в браузере.
Данными веб-архива может воспользоваться каждый желающий совершенно бесплатно. Создавая его, у Брюстера Кайла была основная цель – сохранить культурно-исторические ценности интернет-пространства и создать обширную электронную библиотеку.
В 2001 году был создан основной сервис Internet Archive Wayback Machine, который и сегодня можно найти по адресу https://archive.org. Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
Чтобы не ограничиваться коллекцией сайтов, в 1999 году начали архивировать тексты, изображения, звукозаписи, видео и программные обеспечения.
В марте 2010 года, на ежегодной премии Free Software Awards, Архив Интернета был удостоен звания победителя в номинации Project of Social Benefit.
С каждым годом библиотека разрастается, и уже в августе 2016 года объем Webarchive составил 502 миллиарда копий веб-страниц. Все они хранятся на очень больших серверах в Сан-Франциско, Новой Александрии и Амстердаме.
Как пользоваться веб-архивом?
В том, как пользоваться веб-архивом, нет ничего сложного. Для того, чтобы использовать его, достаточно перейти на соответствующий сайт archive.org и в поиске вести адрес нужного сайта. После непродолжительного времени, архив выдаст информацию об имеющихся сохранениях этого ресурса.
Например, с помощью этого можно найти информацию с сайта, который по каким-либо причинам перестал существовать. Так же веб архив поможет найти информацию со страниц, даже если она была удалена
Это особенно важно для поиска удачных примеров сторителлинга лет. Рассмотрим подробнее, как посмотреть архив.
Проекты, предоставляющие историю сайта
Peeep.us в действии
Сегодня существует несколько проектов, которые предоставляют сервисные услуги по отысканию сохраненных копий. Вот некоторые из них:
- Самым популярным и востребованным у пользователей является web.archive.org. Представленный сайт считается наиболее старым на просторах интернета, создание датируется 1996 годом. Сервис проводит автоматический и ручной сбор данных, а вся информация размещается на огромных заграничных серверах.
- Вторым по популярности сайтом считается peeep.us. Ресурс весьма интересен, ведь его можно использовать для сохранения копии информационного потока, который доступен только вам. Заметим, что проект работает со всеми доменными именами и расширяет границы использования веб-архивов. Что касается полноты информации, то представленный сайт не сохраняет картинки и фреймы. С 2015 года также внесен в список запрещенных на территории России.
- Аналогичным проектом, который описывали выше, является archive.is. К отличиям можно отнести полноту сбора информации, а также возможности сохранения страниц из социальных сетей. Поэтому если вы утеряли пост или интересную информацию, можно выполнить поиск через веб-архив.
Принцип работы веб-архива
Прежде чем пытаться восстанавливать сайт из веб-архива, необходимо понять принцип его работы, который является не совсем очевидным. С особенностями работы сталкиваешься только тогда, когда скачаешь архив сайта. Вы наверняка замечали, попадая на тот или иной сайт, сообщение о том, что домен не продлен или хостинг не оплачен. Поскольку бот, который обходит сайты и скачивает страницы, не понимает что подобная страница не является страницей сайта, он скачивает её как новую версию главной страницы сайта.
Таким образом получается если мы скачаем архив сайта, то вместо главной страницы будем иметь сообщение регистратора или хостера о том, что сайт не работает. Чтобы этого избежать, нам необходимо изучить архив сайта. Для этого потребуется просмотреть все копии и выбрать одну или несколько где на главной странице страница сайта, а не заглушка регистратора или хостера.
«Archivarix» — оптимальный инструмент для новичков и профессионалов
«Archivarix» представляет собой бесплатную СМS, которая имеет открытый исходный код, а также онлайн-загрузчик и восстановитель веб-сайтов из «Веб Архива».
И это — ключевое преимущество «Archivarix», ведь чтобы восстановить удаленный ресурс самостоятельно (из Веб Архива) необходимо владеть языками веб-программирования и иметь определенный опыт в сайтостроении, тогда как «Archivarix» предлагает восстановление и загрузку работоспособной копии удаленного сайта буквально в «один клик»!
Кроме автоматизации и простоты сервис может похвастаться доступной ценовой политикой.
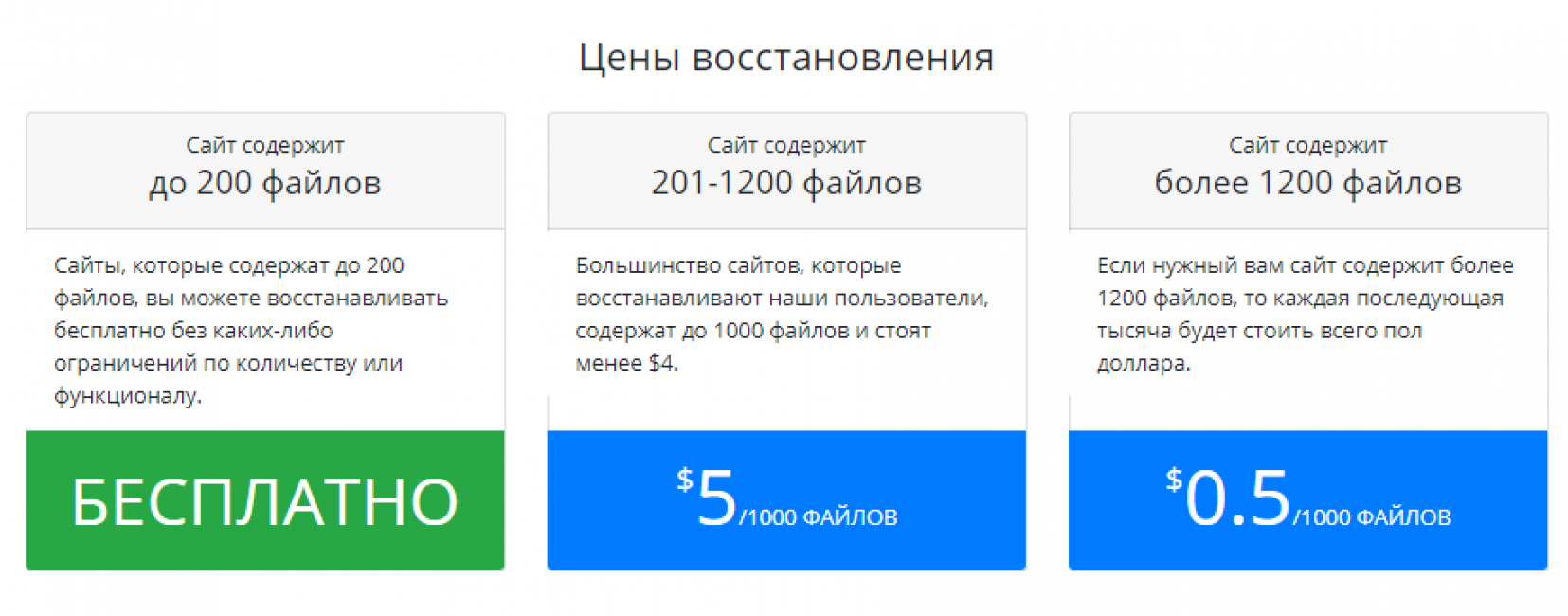
Тарифные планы сервиса Archivarix
Тарифный план: Бесплатно
Однако при условии, что восстанавливаемый сайт содержит не более двух сотен файлов в своем составе, при этом каких-либо ограничений по функционалу сервис не устанавливает. Восстанавливать можно такие сайты можно без каких-либо ограничений по количеству и времени.
Данный тарифный план идеально подойдет для новичков, потому как позволит оценить функционал сервиса и его преимущества непосредственно на практике. А еще этот тариф подойдет тем пользователям, о которых говорится в самом начале данной статьи. Обладатели некогда удаленных личных дневников и блогов (некоммерческой направленности, ведь зачастую именно такие сайты содержат малое число файлов) смогут совершено бесплатно и полностью восстановить свой ресурс, а заодно и бесценные воспоминания.
Тарифный план: $5 за 1000 файлов
Восстановление удаленных сайтов, которые содержат в своем составе от 201 до 1200 файлов (а таких по статистике — подавляющее большинство), попадают под действие второго тарифа, в котором стоимость за 1000 файлов составляет 5 долларов США.
Справедливости ради стоит отметить, что стоимость взимается за количество файлов (по факту). Иными словами, если ресурс имеет в своем наличии, например, 800 файлов, то и стоимость будет немногим менее пяти долларов.
Тарифный план: $0,5 за 1000 файлов
Бывшие владельцы крупных информационных порталов, статейников и/или новостных ресурсов, а также других типов сайтов, содержащих в себе 1200 файлов и более, могут воспользоваться последним тарифом.
Он предусматривает стоимость 0,5 долларов США за каждую 1000 файлов, при условии что восстанавливаемый веб-ресурс «вмещает» не менее 1200.
But What if a Page I want to See is not in the Archive?
Firstly… don’t panic!
It would be a pain a page you wanted to examine was not in the archive. Especially if you wanted to do some of the research I’ve discussed above. The Wayback Machine homepage has a tool that you can use to snapshot a page immediately though. Of course this won’t help to examine a particular issue in the past. But you could at least start archiving the site so it’s available in future.
Type the page URL into the “Save Page Now” box and Wayback Machine will add it to the archive immediately.
The tool will save the page along with any images and CSS it finds there. However, it will not crawl any links it finds on the page and so will not archive the whole domain.
You can add more pages to the archive from a site, but you have to use the “Save Page Now” tool for each one.
If you have concerns about privacy, archive.org does not retain IP addresses on submissions you make to it. So whenever you use the tool your activity is anonymous.
One final note. When a page is archived there is no guarantee when it will be snapshotted again. So you might return to the site again and see only the version that you submitted. Having said this, Wayback Machine will revisit archived pages at some point and the calendar will show this.
Цензура и другие угрозы
archive.org в настоящее время заблокирован в Китае . После того, как террористическая организация «Исламское государство» была запрещена, Интернет-архив был полностью заблокирован в России в течение короткого периода в 2015–2016 годах, в котором размещалось информационное видео этой организации. С 2016 года веб-сайт вернулся и стал доступен полностью, хотя местные коммерческие лоббисты подали иск против Интернет-архива в местный суд, чтобы запретить его на основании авторских прав.
Элисон Макрина , директор проекта «Библиотечная свобода», отмечает, что «библиотекари глубоко ценят личную неприкосновенность частной жизни, но мы также категорически против цензуры».
По крайней мере, в одном случае статья была удалена из архива вскоре после того, как она была удалена с исходного сайта. Daily Beast репортер написал статью , в которой outed несколько гей — олимпийцы спортсменов в 2016 году после того, как он сделал профиль поддельного создают как гея на приложении знакомств. Daily Beast удалила статью после того, как она вызвала всеобщий фурор; Вскоре после этого Интернет-архив сделал то же самое, но решительно заявил, что они сделали это не по какой-либо другой причине, кроме как для защиты безопасности выбывших спортсменов.
Другие угрозы включают стихийные бедствия, разрушение (удаленное или физическое), манипуляции с содержимым архива (см. Также: кибератаки , резервное копирование ), проблемные законы об авторском праве и наблюдение за пользователями сайта.
Александр Роуз, исполнительный директор Long Now Foundation , подозревает, что в долгосрочной перспективе несколько поколений «почти ничего» выживут с пользой, заявляя: «Если у нас будет преемственность в нашей технологической цивилизации, я подозреваю, что многие голые данные останутся доступными для поиска и поиска. Но я подозреваю, что почти ничто из формата, в котором они были доставлены, не будет узнаваемым, «потому что сайты» с глубокими внутренними компонентами систем управления контентом, таких как Drupal, Ruby и Django, труднее заархивировать.
В статье, посвященной сохранению человеческих знаний, The Atlantic отметила, что Интернет-архив, который описывает себя как построенный на долгосрочную перспективу, «яростно работает над сбором данных до того, как они исчезнут без какой-либо долгосрочной инфраструктуры. из.»
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
web.archive.org


В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
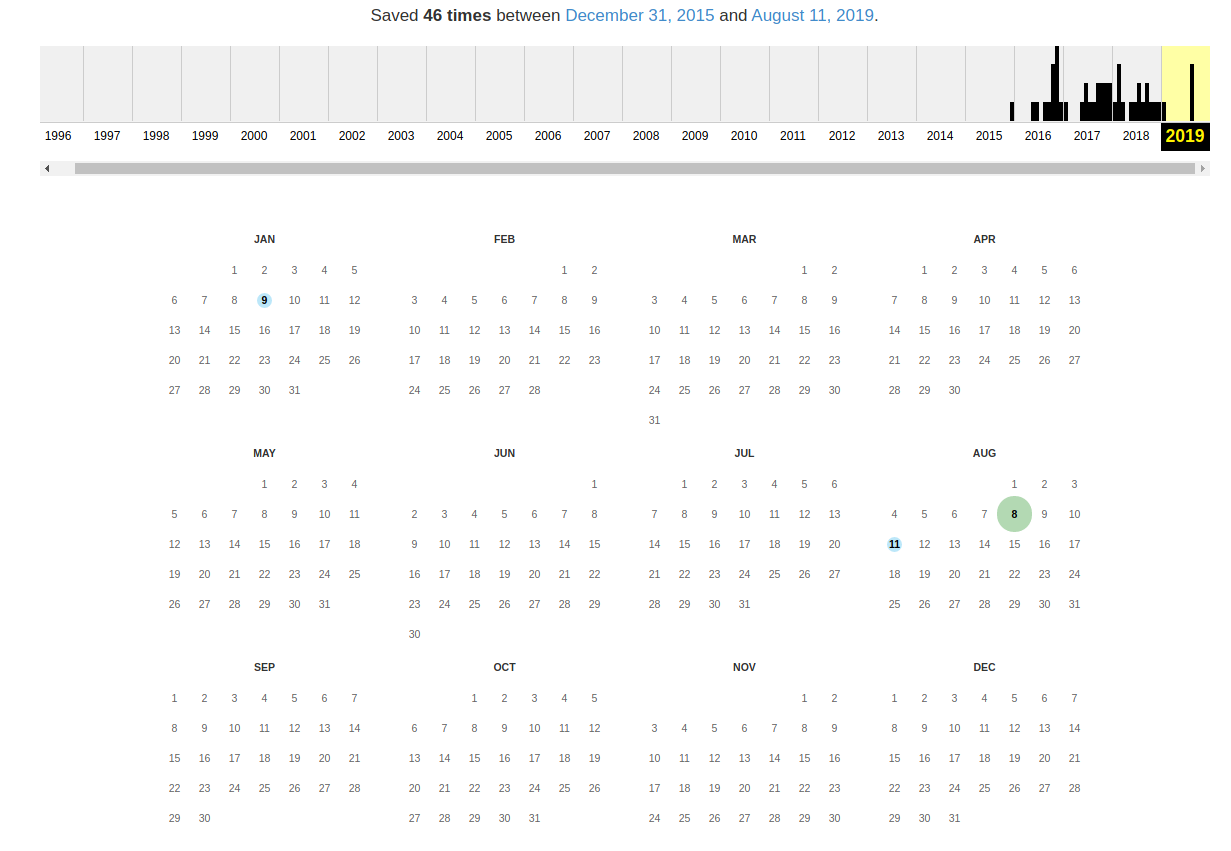
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.


Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
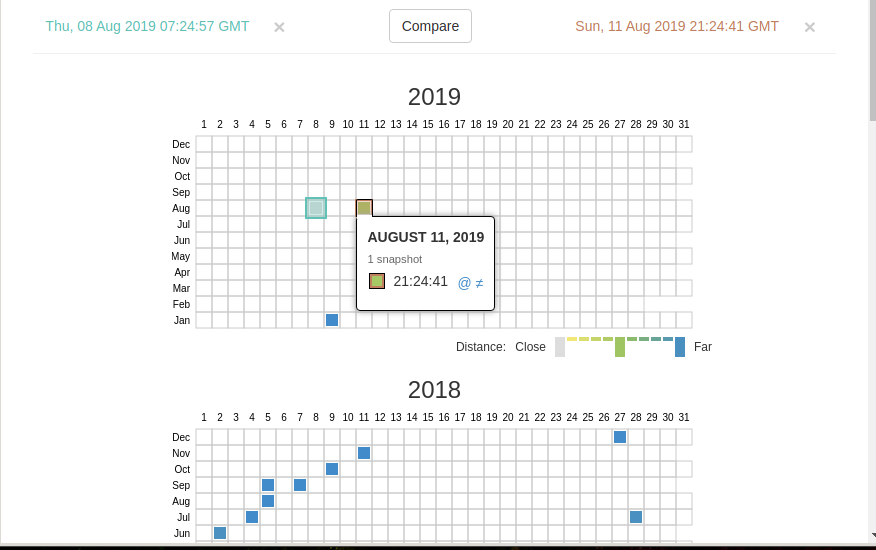
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
В этой вкладке статистика о количестве изменений MIME-типов.
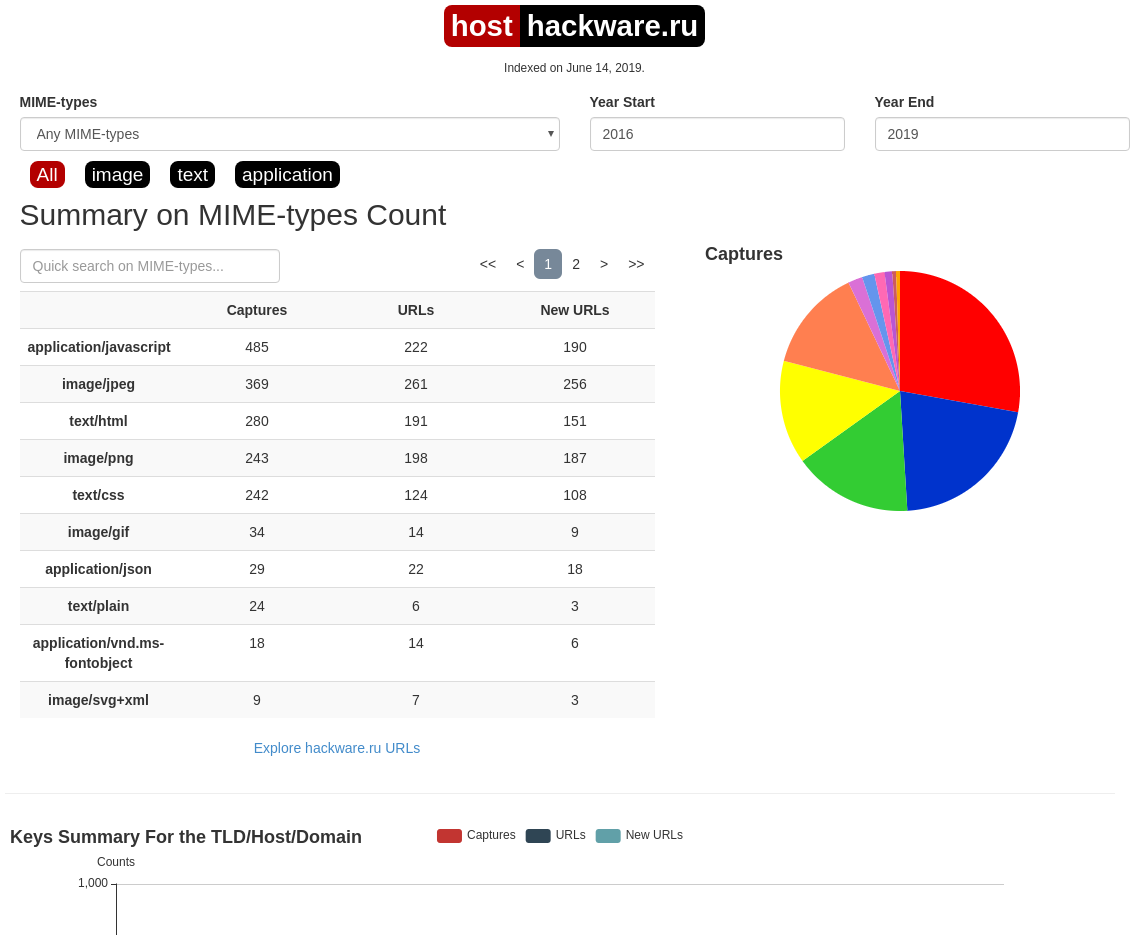
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
Как использовать веб-архив?
Форма для поиска информации на Peeep.us
Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Восстановление сайта из веб архива
Восстановить удаленный либо взломанный хакерами сайт поможет веб-архив. Восстановление каждой отдельной HTML-страницы проекта слишком трудоемкий процесс, поэтому предпочтительнее использовать специальные программы для парсинга WEB-архива.
Как парсить веб-архив с помощью Robotools
Для скачивания сайта с помощью данного сервиса необходимо выбрать подходящий тариф в зависимости от количества веб-страниц на проекте:
Протестировать работу сервиса можно в , после регистрации будет доступно 25 страниц бесплатно:
Перейдем в раздел «Мои задачи», укажем домен, на котором ранее функционировал нужный сайт и нажмем «Запуск»:
Затем выбираем «Восстановить домен или снимок из веб-архива»:
После этого выбираем нужную дату, количество страниц, действия с внешними ссылками в статьях и нажимаем «Начать процесс восстановления»:
После завершения задачи нажимаем на кнопку для скачивания архива с веб-страницами:
Затем нажимаем «Все ОК, собрать ZIP-архив»:
После этого нажимаем «Скачать архив»:
В данном примере рассматривалось восстановление сайта на WordPress, получен архив с такими файлами:
Как скачать сайт из веб-архива с помощью Archivarix
Этот сервис также помогает восстановить старые версии сайтов из веб-архива. Цены зависят от количества файлов на проекте. Начнем работу с выбора раздела «Восстановить из веб-архива». Укажем домен и при желании установим временной диапазон, в правой колонке отметим дополнительные параметры восстанавливаемого проекта:
Затем укажем электронный адрес и нажмем «Восстановить»:
Если сайт содержит более 200 файлов, придет уведомление на почту с предложением оплатить восстановление проекта: