Программа для восстановления сайтов из вебархива
Содержание:
- Проекты, предоставляющие историю сайта
- Цензура и другие угрозы
- Всемирный Веб архив сайтов интернета
- Индексация веб-страниц в интернете
- Зачем нужна история сайта
- Что делать, если удалённая страница не сохранена ни в одном из архивов?
- Где можно найти сторис в мобильной версии ВК?
- Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
- Архив сайтов Internet Archive Wayback Machine
- Что можно изменить
- Что такое веб-архив
- Как найти уникальный контент для своего сайта
- Качаем сайт с web.archive.org
- Примечания[ | ]
- Мнения в Сторис
Проекты, предоставляющие историю сайта
Peeep.us в действии
Сегодня существует несколько проектов, которые предоставляют сервисные услуги по отысканию сохраненных копий. Вот некоторые из них:
- Самым популярным и востребованным у пользователей является web.archive.org. Представленный сайт считается наиболее старым на просторах интернета, создание датируется 1996 годом. Сервис проводит автоматический и ручной сбор данных, а вся информация размещается на огромных заграничных серверах.
- Вторым по популярности сайтом считается peeep.us. Ресурс весьма интересен, ведь его можно использовать для сохранения копии информационного потока, который доступен только вам. Заметим, что проект работает со всеми доменными именами и расширяет границы использования веб-архивов. Что касается полноты информации, то представленный сайт не сохраняет картинки и фреймы. С 2015 года также внесен в список запрещенных на территории России.
- Аналогичным проектом, который описывали выше, является archive.is. К отличиям можно отнести полноту сбора информации, а также возможности сохранения страниц из социальных сетей. Поэтому если вы утеряли пост или интересную информацию, можно выполнить поиск через веб-архив.
Цензура и другие угрозы
archive.org в настоящее время заблокирован в Китае . После того, как террористическая организация «Исламское государство» была запрещена, Интернет-архив был полностью заблокирован в России в течение короткого периода в 2015–2016 годах, в котором размещалось информационное видео этой организации. С 2016 года веб-сайт вернулся и стал доступен полностью, хотя местные коммерческие лоббисты подали иск против Интернет-архива в местный суд, чтобы запретить его на основании авторских прав.
Элисон Макрина , директор проекта «Библиотечная свобода», отмечает, что «библиотекари глубоко ценят личную неприкосновенность частной жизни, но мы также категорически против цензуры».
По крайней мере, в одном случае статья была удалена из архива вскоре после того, как она была удалена с исходного сайта. Daily Beast репортер написал статью , в которой outed несколько гей — олимпийцы спортсменов в 2016 году после того, как он сделал профиль поддельного создают как гея на приложении знакомств. Daily Beast удалила статью после того, как она вызвала всеобщий фурор; Вскоре после этого Интернет-архив сделал то же самое, но решительно заявил, что они сделали это не по какой-либо другой причине, кроме как для защиты безопасности выбывших спортсменов.
Другие угрозы включают стихийные бедствия, разрушение (удаленное или физическое), манипуляции с содержимым архива (см. Также: кибератаки , резервное копирование ), проблемные законы об авторском праве и наблюдение за пользователями сайта.
Александр Роуз, исполнительный директор Long Now Foundation , подозревает, что в долгосрочной перспективе несколько поколений «почти ничего» выживут с пользой, заявляя: «Если у нас будет преемственность в нашей технологической цивилизации, я подозреваю, что многие голые данные останутся доступными для поиска и поиска. Но я подозреваю, что почти ничто из формата, в котором они были доставлены, не будет узнаваемым, «потому что сайты» с глубокими внутренними компонентами систем управления контентом, таких как Drupal, Ruby и Django, труднее заархивировать.
В статье, посвященной сохранению человеческих знаний, The Atlantic отметила, что Интернет-архив, который описывает себя как построенный на долгосрочную перспективу, «яростно работает над сбором данных до того, как они исчезнут без какой-либо долгосрочной инфраструктуры. из.»
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.

Главная страница сайта Archive.org
Индексация веб-страниц в интернете
Начиная с 1996 года по настоящее время на сайте archive.org собрано более 466 миллиардов веб-страниц (эта цифра все время увеличивается). Архив страниц интернета создан для сохранения, ознакомления и изучения имеющей информации, которая накопилась за все эти годы во всемирной сети.
Время от времени, специальные роботы, принадлежащие сервису, индексируют содержание практически всех сайтов в интернете
Следует принять во внимание, что во время обхода робота для индексации сайтов, на некоторых сайтах могли возникать внутренние проблемы: сайт, или некоторые страницы сайта были недоступны, сайт находился на техобслуживании, не работали подключаемые внешние элементы и т. д
Поэтому некоторые архивы сайтов будут полными, а некоторые снимки (архивы) могут содержать только частичную информацию. Имейте в виду, что некоторые сайты индексируются часто, другие сайты, наоборот, довольно редко.
Для просмотра веб-страниц используется онлайн сервис The Wayback Machine. В Internet Archive доступны для просмотра не только действующие в настоящий момент сайты, но и сайты, которые уже не существуют. С помощью архива интернета можно побывать на прекративших существование сайтах, и ознакомится с содержимым веб-страниц удаленных сайтов.
Благодаря замечательному архиву сайтов интернета можно проследить историю изменений, как изменялся внешний облик сайта и его содержимое с течением времени, использовать архивы для восстановления сайта, искать необходимую информацию.
На главной странице сайта archive.org можно получить доступ к архивным данным, которые сгруппированы в тематические разделы, или сразу перейти на страницу сервиса Wayback Machine.
Зачем нужна история сайта
Хронография домена зачастую выдаёт информацию о нём с момента создания. Виртуальные архивы сайтов также дают возможность узнать:
- сколько времени существует домен;
- как выглядел сайт раньше, вплоть до конкретной даты;
- тематику сайта в прошлом;
- наличие банов, фильтров, санкций в прошлом, действуют ли они сейчас;
- количество владельцев ресурса;
- другие домены в пределах сервера, на котором был сайт.
При помощи архивных данных можно восстановить информацию, которая была утеряна. Например, если при обновлении баз данных либо смене шаблона сайт перестал работать, можно восстановить сайт из веб-архива по дате и скопировать оттуда старые тексты.
Бывает и так: анализ трафика показал, что при прошлом дизайне сайт приносил больше прибыли. Сравнение текущей и прошлой версий одного ресурса позволяет сделать соответствующие выводы и улучшить работу.
В отличие от старых доменов, новые всегда обладают чистой историей, ведь у них не было владельцев, и они не были зарегистрированы как сайты. Такие домены покупают, не боясь столкнуться с фильтрами и другими проблемами. Однако многие вебмастера предпочитают покупать готовые сайты с рук или на аукционах. Причина здесь одна: старый домен с хорошей историей легче продвинуть в поиске, чем начинать оптимизацию с чистого листа.
При покупке старого сайта нужно тщательно проверять его прошлое
Важно, чтобы на сайте не было ворованного контента, запрещённых тематик и банов по причине любых нарушений
Чтобы убедиться, что вы покупаете не кота в мешке, вы можете пройтись по нашему чеклисту «Как проверить сайт перед покупкой».
Изначально, популярнейший поисковик Гугл назывался BackRub. И выглядел как-то стрёмно и совершенно непонятно.
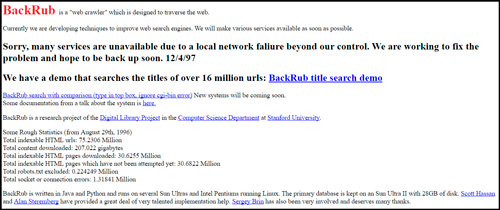
Лишь в 1998 он принял более современный внешний вид. Тогда еще, в конце слова Google стоял восклицательный знак. Представляете, это бета версия, то есть тестовая. Тогда еще разработчики исправляли ошибки и проверяли как все работает. Эх, где мои 16 лет.
Уже тогда здесь было две кнопки. Одна со стандартным поиском, а вторая выбирает случайную страницу с информацией. Если бы администраторы убрали кнопку «Мне повезет», которая пользуется бешенной популярностью и по сей день, то смогли бы получать дополнительный доход с рекламы. Он составил бы примерно 100 миллионов долларов в год. Но, они не жадные.
Кстати о деньгах, компания Mozilla ежегодно получает от гугла 300 миллионов за то, что в их браузере по умолчанию стоит поисковая система от Google.

Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
cache:URL
Например:
cache:https://hackware.ru/?p=6045
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
Например, текстовый вид:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=1&vwsrc=0
Исходный код:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=0&vwsrc=1
Где можно найти сторис в мобильной версии ВК?
После того как разработчики приложения внесли опцию сохранения сторис, публикации не удаляются в автоматическом режиме безвозвратно. Сохраняются видеоролики в специальном разделе – архив. Все ваши публикации будут находиться именно в архиве.
Инструкция как открыть архив в мобильной версии ВК:
- Открываем главную страницу вашего профиля, затем кликаем на 3 точки верху экрана.

Находим три точки на профиле
- В открытом меню выбираем «Архив историй»;

Нажимаем на «Архив историй»
- Загружается список ваших историй за действующий месяц.

Архив историй
Открывая историю, можно посмотреть, кто видел их, данная информация представлена в качестве иконки в виде глаза. В одном из углов экрана будут размещены 3 точки. Если кликнуть на них появиться меню, как раз из него можно будет и сохранить историю на мобильный телефон.
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
 После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
 Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
 Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page
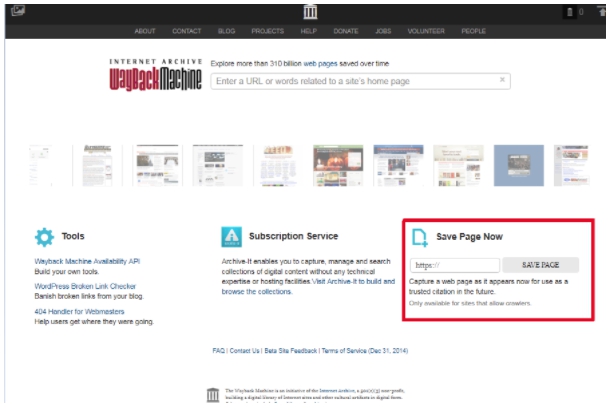 Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
Архив сайтов Internet Archive Wayback Machine
Скрыть рекламу в статье
Архив сайтов Internet Archive Wayback Machine
Каждый, кто собирал информацию по интересующей его проблеме за достаточно длительный период, знает, как порой бывает важно найти сведения, опубликованные на сайте несколько лет назад. Иногда это просто необходимо: в частности, в случае обнаружения новых тенденций в развитии объекта, которое требует ретроспективной оценки времени их появления
Либо возникновения новой темы для изучения событий на рынке и, как следствие, сравнения реакции на них с тем, как вели себя в подобной ситуации участники рынка в прошлом. Конечно, специалист конкурентной разведки всегда старается архивировать интересующую его информацию. Однако в реальной жизни бывает так, что проблема просто не входила в сферу его интересов до определенного момента либо на предприятии эта служба появилась позже тех событий, которые и стали предметом ее пристального внимания.
В таком случае на помощь нередко может прийти сервис, который нам также рекомендовал Arthur Weiss. Этот Internet Archive Wayback Machine, его изображение представлено на рис. 21. Сервис позиционируется как «Библиотека Интернета». Пауки, принадлежащие Internet Archive Wayback Machine, посещают веб-сайты и сохраняют архивную копию на сервере «библиотеки». Как написано на странице этого ресурса, интересующего нас сайта может и не оказаться в архиве. Например, в случае если паук не может его прочитать, поскольку тот защищен одним из способов, описанных нами в соответствующем разделе данной книги.
Сервис Internet Archive Wayback Machine некоммерческий. Он работает с 1996 г. и, как утверждают его владельцы, существует на пожертвования меценатов и благодаря технической поддержке крупных интернет-компаний, таких как Alexa. Ежемесячно архив увеличивается в объеме на 20 терабайт. Ценным нам видится то обстоятельство, что Internet Archive Wayback Machine отслеживает копии даже тех сайтов, которых больше не существует в Сети.
Для того, чтобы увидеть сохраненную версию нужного сайта, достаточно ввести в окно, расположенное в верхней части главной страницы, адрес ресурса и нажать клавишу «Take me Back». После этого пользователю будет предложен архив по запрошенному ресурсу. В пределах этого архива можно ознакомиться с копией сайта за искомую дату. На рис. 22 показан список копий ресурса «Росбизнесконсалтинг».
Рис. 21. Главная страница Internet Archive Wayback Machine.
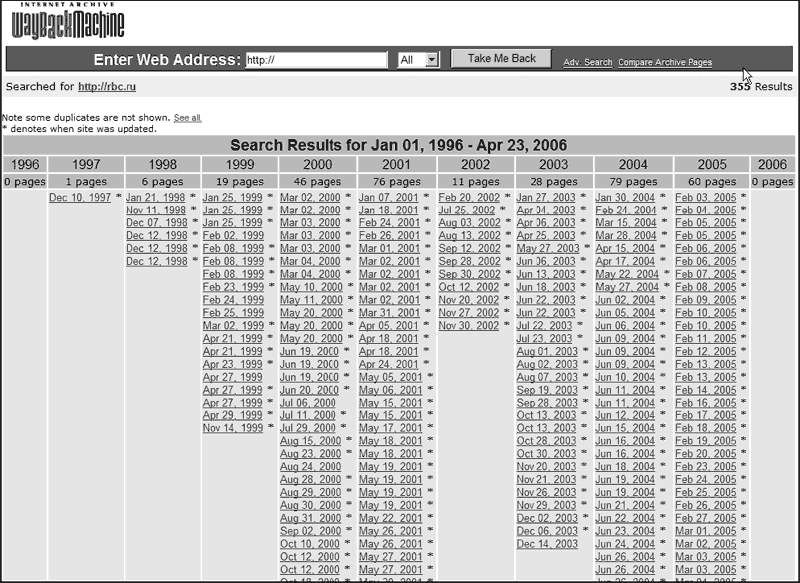
Архив, расположенный на сервере в Сан-Франциско, поражает своими возможностями. Вот как выглядела страница этого известнейшего интернет-ресурса 10 декабря 1997 г. (рис. 23).

Рис. 23. Страница ресурса РБК от 10 декабря 1997 г.
Надо сказать, что, помимо функций обеспечения нужд непосредственно конкурентной разведки, наши источники рассказывали о случаях, когда этот ресурс помогал компаниям в сборе доказательств по фактам информационной войны против них. Как правило, в таких ситуациях, когда нападающая сторона «затирала» сведения на сайте, Internet Archive Wayback Machine позволял доказать факт распространения порочащих организацию данных.
Один из источников автора сообщил о факте, когда наличие копии сайта в архиве Internet Archive Wayback Machine позволило доказать в споре с контролирующими органами, что сайт, существование которого вызывало сомнения у контролеров, действительно существовал в тот период, когда компания получила деньги за его разработку и «раскрутку».
Оглавление книги
Что можно изменить
«ВКонтакте» постоянно совершенствует возможности своего интерфейса. То, что видят другие пользователи, можно редактировать во вкладке приватности. Там можно указать кто видит: главную информацию, сохраненные фото, список групп, аудиозаписи, подарки и прочее.
Также указывается можно ли оставлять записи, и многое другое.
Есть еще одна функция – закрытый профиль. Кого нет в списке друзей не смогут просматривать информацию о хозяине страницы, кроме главного фото, статуса и основных данных. Чтобы закрыть профиль, нужно зайти в настройки выбрать приватность и в разделе «Прочее» выбрать тип профиля – закрытый.
Что такое веб-архив
Веб-архив сайтов позиционируется как своеобразная бесплатная машина времени, позволяющая вернуться на месяцы или годы назад, чтобы увидеть, как выглядел ресурс на тот момент. При этом у каждого сайта сохраняются многочисленные версии от разных дат, которые зависят от посещений проекта краулерами веб-архива. У популярных сайтов может сохраняться тысячи версий, которые обновлялись ежедневно множество раз на протяжении всего периода существования проекта:
Веб-архив основан в начале 1996 года и с этого времени в нем сохранено более 330 миллиардов веб-страниц, включая 20 миллионов книг, 4,5 миллионов аудиофайлов и 4 миллиона видео, занимающие свыше тысячи терабайт. Ежедневно сайт посещают миллионы пользователей, и он входит в ТОП-300 самых популярных проектов мира.
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Примечания[ | ]
- Internet Archive: Bios (англ.) — Internet Archive .
- Глобальный рейтинг сайта archive.org (англ.). Alexa Internet. Дата обращения 20 июня 2020.
- https://projects.propublica.org/nonprofits/organizations/943242767
- 10,000,000,000,000,000 bytes archived! (неопр.) . Архивировано 28 ноября 2012 года.
- Defining Web pages, Web sites and Web captures (неопр.) .
- Donate to the Internet Archive! (англ.). archive.org. Дата обращения 28 марта 2020.
- Internet Archive officially a library (неопр.) .Internet Archive (7 мая 2007). Дата обращения 31 августа 2020.
- Internet Archive: In the Collections (неопр.) (недоступная ссылка).Wayback Machine (6 июня 2000). Дата обращения 1 сентября 2020. Архивировано 6 июня 2000 года.
- Bowman, Lisa M . Net archive silences Scientology critic, CNET News.com (24 сентября 2002). Архивировано 16 июля 2012 года. Дата обращения 4 января 2007.
- Jeff. exclusions from the Wayback Machine(неопр.) (Blog).Wayback Machine Forum . Internet Archive (23 сентября 2002). Дата обращения 4 января 2007. Архивировано 25 августа 2011 года.Author and Date indicate initiation of forum thread
- Miller, Ernest Sherman, Set the Wayback Machine for Scientology(неопр.) (Blog).LawMeme . Yale Law School (24 сентября). Дата обращения 4 января 2007. Архивировано 25 августа 2011 года.The posting is billed as a ‘feature’ and lacks an associated year designation; comments by other contributors appear after the ‘feature’
- Maximillian Dornseif. Government mandated blocking of foreign Web content (англ.).preprint cs/0404005 16. arXiv (2004). Дата обращения 26 ноября 2020.
- Bulk Access to OCR for 1 Million Books, via Open Library Blog, by raj, 24 ноября 2008. (неопр.) . Архивировано 28 ноября 2012 года.
- Free Software Awards Announced (неопр.) . Архивировано 28 ноября 2012 года.
- Стали известны номинанты ежегодной награды Free Software Awards (неопр.) (недоступная ссылка). Дата обращения 17 сентября 2020. Архивировано 18 июля 2011 года.
- Производится блокировка экстремистского видео террористической организации «Исламское государство Ирака и Леванта» в сети Интернет (неопр.) . Роскомнадзор (24 октября 2014).
- Роскомнадзор внёс «архив интернета» в реестр запрещённых сайтов // Meduza. — 2014. — 25 октября.
- ↑ 12 Роскомнадзор заблокировал архив интернета // РБК. 25 июня 2015 года.
- Роскомнадзор заблокировал страницу «архива интернета» за экстремизм // Lenta.ru. 25 июня 2020 года.
- Роскомнадзор заблокировал архив интернета из-за «Одиночного джихада» // Московский комсомолец. 25 июня 2020 года.
- АЗАПИ хочет навечно заблокировать «Архив интернета» // РосКомСвобода. — 2014. — 22 августа.
- Xenia Voronina . Experts explain reason for websites blocking in Kazakhstan (англ.), Республиканская газета «Казахстанская правда» (21 October 2015). Дата обращения 26 ноября 2020.
- Kyrgyzstan Blocks Archive.org on ‘Extremism’ Grounds (англ.), Global Voices advox (21 July 2017). Дата обращения 26 ноября 2017.
- ‘Bollywood blocks the Internet Archive’ — BBC News
- Access to Internet Archive’s Wayback Machine Blocked in India
- Statement and Questions Regarding an Indian Court’s Order to Block archive.org | Internet Archive Blogs
- Update: Internet Archive contacted Indian govt regarding the block, but got no response — MediaNama
Мнения в Сторис
Создатели социальной сети стараются вносить изменения и новые опции ВК, чтобы пользователям было интересно и весело. Теперь каждый может воспользоваться опцией мнения в сторис. Это функция позволяет выразить собственное мнение относительно того или иного вопроса, процесса, новости. Также можно другим юзерам, своим подписчикам. Чтобы воспользоваться такой опцией нужно:
- Открыть новости, где доступны сторис.
- Далее нажимаем на создание новой публикации.

Создаем новую публикацию
- Делаем селфи или же добавляем другое изображение.
- Жмем на кнопку в виде наклейки.
- Кликаем на стикер мнения.
- Из представленного перечня нужно выбрать тот, который вас заинтересовал, и вводим вопрос.
Такая история также будет храниться в архиве социальной сети, и при желании вы сможете ее просмотреть. После того как юзеры выберут ее, появится форма для ввода ответа на вопрос. Отвечающий при желании может указать имя или же остаться анонимом.