Функции numpy.linspace() и numpy.arange() в python
Содержание:
- Агрегирование в NumPy
- Статистика¶
- Трансляция с помощью numpy.where()
- Реверсив Numpy Array в Python
- Добро пожаловать в NumPy!
- Установка NumPy
- Как импортировать NumPy
- В чем разница между списком Python и массивом NumPy?
- Что такое массив?
- Перестройка массива
- Импорт данных из CSV
- Фундаментальный элемент NumPy – массив (array)
- Параметры Numpy Random normal()
- Python numpy nanmax
- Тест производительности
- Синтаксис
- Примеры функции Numpy Add
- Pandas – удобство использования превыше всего
- DataFrame
- Основы метода Numpy arange()
- Python numpy nan to zero
- Можем Ли Мы Найти Сложение Между Двумя Массивами Numpy С Разными Формами?
- Параметры
- Примеры работы с NumPy
- Пример 4: Пример плитки Numpy в 2-D массиве
- Пример 2: Numpy Плитка Вертикально
- Сравнение numpy.arange() и range()
- 7.3. Статистика
- Функции sum, mean, min и max
Агрегирование в NumPy
Дополнительным преимуществом NumPy является наличие в нем функций агрегирования:
Функциями , и дело не ограничивается.
К примеру:
- позволяет получить среднее арифметическое;
- выдает результат умножения всех элементов;
- нужно для среднеквадратического отклонения.
Это лишь небольшая часть довольно обширного списка функций агрегирования в NumPy.
Использование нескольких размерностей NumPy
Все перечисленные выше примеры касаются векторов одной размерности. Главным преимуществом NumPy является его способность использовать отмеченные операции с любым количеством размерностей.
Статистика¶
| Команда | Описание |
|---|---|
| amin(a) | минимум в массиве или минимумы вдоль одной из осей |
| amax(a) | максимум в массиве или максимумы вдоль одной из осей |
| nanmax(a) | максимум в массиве или максимумы вдоль одной из осей (игнорируются NaN). |
| nanmin(a) | минимум в массиве или минимумы вдоль одной из осей (игнорируются NaN). |
| ptp(a) | диапазон значений (максимум — минимум) вдоль оси |
| average(a) | взвешенное среднее вдоль оси |
| mean(a) | арифметическое среднее вдоль оси |
| median(a) | вычисление медианы вдоль оси |
| std(a) | стандартное отклонение вдоль оси |
| corrcoef(x) | коэффициенты корреляции |
| correlate(a, v) | кросс-корреляция двух одномерных последовательностей |
| cov(m) | ковариационная матрица для данных |
| histogram(a) | гистограмма из набора данных |
| histogram2d(x, y) | двумерная гистограмма для двух наборов данных |
| histogramdd(sample) | многомерная гистограмма для данных |
| bincount(x) | число появление значения в массиве неотрицательных значений |
| digitize(x, bins) | возвращает индексы интервалов к которым принадлежат элементы массива |
Трансляция с помощью numpy.where()
Если мы предоставим все массивы condition, x и y, numpy будет транслировать их вместе.
import numpy as np a = np.arange(12).reshape(3, 4) b = np.arange(4).reshape(1, 4) print(a) print(b) # Broadcasts (a < 5, a, and b * 10) # of shape (3, 4), (3, 4) and (1, 4) c = np.where(a < 5, a, b * 10) print(c)
Вывод
] `0 1 2 3` ]
Опять же, здесь вывод выбирается на основе условия, поэтому все элементы, но здесь b, транслируются в форму a. (Одно из его измерений имеет только один элемент, поэтому при трансляции ошибок не будет).
Итак, b теперь станет ], и теперь мы можем выбирать элементы даже из этого транслируемого массива. Таким образом, форма вывода такая же, как у файла.
Реверсив Numpy Array в Python
Модуль позволяет нам использовать массив Структуры данных в Python, которые действительно быстро И разрешить только такие же массивы типа данных.
Здесь мы собираемся обратить вспять массив в Python, построенный с помощью Numpy Module.
1. Использование метода FLIP ()
Метод в модуле Numpy переворачивает порядок Numpy Array и возвращает объект Numpy Array.
import numpy as np
#The original NumPy array
new_arr=np.array()
print("Original Array is :",new_arr)
#reversing using flip() Method
res_arr=np.flip(new_arr)
print("Resultant Reversed Array:",res_arr)
Выход :
Original Array is : Resultant Reversed Array:
2. Использование метода flipud ()
метод еще один метод в Numpy Модуль, который переворачивает массив вверх/вниз. Он также может быть использован, чтобы изменить номерного массива в Python. Давайте посмотрим, как мы можем использовать его в небольшом примере.
import numpy as np
#The original NumPy array
new_arr=np.array()
print("Original Array is :",new_arr)
#reversing using flipud() Method
res_arr=np.flipud(new_arr)
print("Resultant Reversed Array:",res_arr)
Выход :
Original Array is : Resultant Reversed Array:
3. Используя простые нарезки
Как мы делали ранее со списками, мы можем поменять массив в Python, построенный с Numpy, используя нарезка Отказ Мы создаем новый Numpy объект массива, который содержит элементы в обратном порядке.
import numpy as np
#The original NumPy array
new_arr=np.array()
print("Original Array is :",new_arr)
#reversing using array slicing
res_arr=new_arr
print("Resultant Reversed Array:",res_arr)
Выход :
Original Array is : Resultant Reversed Array:
Добро пожаловать в NumPy!
NumPy (NumericalPython) — это библиотека Python с открытым исходным кодом, которая используется практически во всех областях науки и техники. Это универсальный стандарт для работы с числовыми данными в Python, и он лежит в основе научных экосистем Python и PyData. В число пользователей NumPy входят все — от начинающих программистов до опытных исследователей, занимающихся самыми современными научными и промышленными исследованиями и разработками. API-интерфейс NumPy широко используется в пакетах Pandas, SciPy, Matplotlib, scikit-learn, scikit-image и в большинстве других научных и научных пакетов Python.
Библиотека NumPy содержит многомерный массив и матричные структуры данных (дополнительную информацию об этом вы найдете в следующих разделах). Он предоставляет ndarray, однородный объект n-мерного массива, с методами для эффективной работы с ним. NumPy может использоваться для выполнения самых разнообразных математических операций над массивами. Он добавляет мощные структуры данных в Python, которые гарантируют эффективные вычисления с массивами и матрицами, и предоставляет огромную библиотеку математических функций высокого уровня, которые работают с этими массивами и матрицами.
Узнайте больше о NumPy здесь!
GIF черезgiphy
Установка NumPy
Чтобы установить NumPy, я настоятельно рекомендую использовать научный дистрибутив Python. Если вам нужны полные инструкции по установке NumPy в вашей операционной системе, вы можетенайти все детали здесь,
Если у вас уже есть Python, вы можете установить NumPy с помощью
conda install numpy
или
pip install numpy
Если у вас еще нет Python, вы можете рассмотреть возможность использованияанаконда, Это самый простой способ начать. Преимущество этого дистрибутива в том, что вам не нужно слишком беспокоиться об отдельной установке NumPy или каких-либо основных пакетов, которые вы будете использовать для анализа данных, таких как pandas, Scikit-Learn и т. Д.
Если вам нужна более подробная информация об установке, вы можете найти всю информацию об установке наscipy.org,
фотоАдриеннотPexels
Если у вас возникли проблемы с установкой Anaconda, вы можете ознакомиться с этой статьей:
Как импортировать NumPy
Каждый раз, когда вы хотите использовать пакет или библиотеку в своем коде, вам сначала нужно сделать его доступным.
Чтобы начать использовать NumPy и все функции, доступные в NumPy, вам необходимо импортировать его. Это можно легко сделать с помощью этого оператора импорта:
import numpy as np
(Мы сокращаем «numpy» до «np», чтобы сэкономить время и сохранить стандартизированный код, чтобы любой, кто работает с вашим кодом, мог легко его понять и запустить.)
В чем разница между списком Python и массивом NumPy?
NumPy предоставляет вам огромный выбор быстрых и эффективных числовых опций. Хотя список Python может содержать разные типы данных в одном списке, все элементы в массиве NumPy должны быть однородными. Математические операции, которые должны выполняться над массивами, были бы невозможны, если бы они не были однородными.
Зачем использовать NumPy?
фотоPixabayотPexels
Массивы NumPy быстрее и компактнее, чем списки Python. Массив потребляет меньше памяти и намного удобнее в использовании. NumPy использует гораздо меньше памяти для хранения данных и предоставляет механизм задания типов данных, который позволяет оптимизировать код еще дальше.
Что такое массив?
Массив является центральной структурой данных библиотеки NumPy. Это таблица значений, которая содержит информацию о необработанных данных, о том, как найти элемент и как интерпретировать элемент. Он имеет сетку элементов, которые можно проиндексировать в Все элементы имеют одинаковый тип, называемыймассив dtype(тип данных).
Массив может быть проиндексирован набором неотрицательных целых чисел, логическими значениями, другим массивом или целыми числами.рангмассива это количество измерений.формамассива — это кортеж целых чисел, дающий размер массива по каждому измерению.
Одним из способов инициализации массивов NumPy является использование вложенных списков Python.
a = np.array(, , ])
Мы можем получить доступ к элементам в массиве, используя квадратные скобки. Когда вы получаете доступ к элементам, помните, чтоиндексирование в NumPy начинается с 0, Это означает, что если вы хотите получить доступ к первому элементу в вашем массиве, вы получите доступ к элементу «0».
print(a)
Выход:
Перестройка массива
После нарезки данных вам может понадобиться изменить их.
Например, некоторые библиотеки, такие как scikit-learn, могут требовать, чтобы одномерный массив выходных переменных (y) был сформирован как двумерный массив с одним столбцом и результатами для каждого столбца.
Некоторые алгоритмы, такие как рекуррентная нейронная сеть с короткой кратковременной памятью в Keras, требуют ввода данных в виде трехмерного массива, состоящего из выборок, временных шагов и функций.
Важно знать, как изменить ваши массивы NumPy, чтобы ваши данные соответствовали ожиданиям конкретных библиотек Python. Мы рассмотрим эти два примера
Форма данных
Массивы NumPy имеют атрибут shape, который возвращает кортеж длины каждого измерения массива.
Например:
При выполнении примера печатается кортеж для одного измерения.
Кортеж с двумя длинами возвращается для двумерного массива.
Выполнение примера возвращает кортеж с количеством строк и столбцов.
Вы можете использовать размер измерений вашего массива в измерении формы, например, указав параметры.
К элементам кортежа можно обращаться точно так же, как к массиву, с 0-м индексом для числа строк и 1-м индексом для количества столбцов. Например:
Запуск примера позволяет получить доступ к конкретному размеру каждого измерения.
Изменить форму 1D в 2D Array
Обычно требуется преобразовать одномерный массив в двумерный массив с одним столбцом и несколькими массивами.
NumPy предоставляет функцию reshape () для объекта массива NumPy, который можно использовать для изменения формы данных.
Функция reshape () принимает единственный аргумент, который задает новую форму массива. В случае преобразования одномерного массива в двумерный массив с одним столбцом кортеж будет иметь форму массива в качестве первого измерения (data.shape ) и 1 для второго измерения.
Собрав все это вместе, мы получим следующий проработанный пример.
При выполнении примера печатается форма одномерного массива, изменяется массив, чтобы иметь 5 строк с 1 столбцом, а затем печатается эта новая форма.
Изменить форму 2D в 3D Array
Обычно требуется преобразовать двумерные данные, где каждая строка представляет последовательность в трехмерный массив для алгоритмов, которые ожидают множество выборок за один или несколько временных шагов и одну или несколько функций.
Хорошим примером являетсямодель в библиотеке глубокого обучения Keras.
Функция изменения формы может использоваться напрямую, указывая новую размерность. Это ясно с примером, где каждая последовательность имеет несколько временных шагов с одним наблюдением (функцией) на каждый временной шаг.
Мы можем использовать размеры в атрибуте shape в массиве, чтобы указать количество выборок (строк) и столбцов (временных шагов) и зафиксировать количество объектов в 1
Собрав все это вместе, мы получим следующий проработанный пример.
При выполнении примера сначала печатается размер каждого измерения в двумерном массиве, изменяется форма массива, а затем суммируется форма нового трехмерного массива.
Импорт данных из CSV
Мы также можем создать DataFrame, импортировав файл CSV. Файл CSV – это текстовый файл с одной записью данных в каждой строке. Значения в записи разделяются символом «запятая».
Pandas предоставляет полезный метод с именем read_csv() для чтения содержимого файла CSV.
Например, мы можем создать файл с именем «cities.csv», содержащий подробную информацию о городах Индии. Файл CSV хранится в том же каталоге, что и сценарии Python. Этот файл можно импортировать с помощью:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
Наша цель – загрузить данные и проанализировать их, чтобы сделать выводы. Итак, мы можем использовать любой удобный способ загрузки данных.
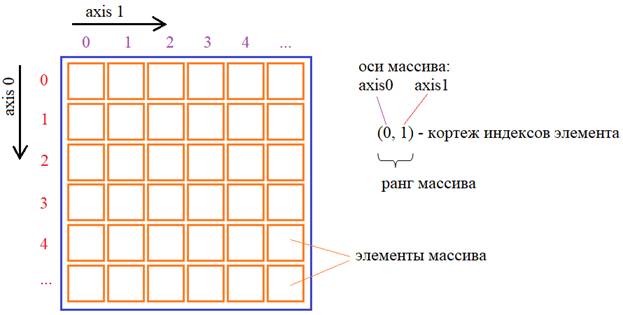
Фундаментальный элемент NumPy – массив (array)
Отлично,
сложнейший этап установки и импорта пакета позади. Пришло время сделать первые
шаги и вначале познакомиться с его фундаментальным элементом – однородным
многомерным массивом. В NumPy элементы массива имеют единый тип
данных. Их индексы описываются кортежем целых неотрицательных чисел.
Размерность кортежа – это ранг массива (то есть, размерность массива), а каждое
число в кортеже представляет свою отдельную ось:
Как создать
массив в NumPy? Существует много
способов, но базовый реализуется через функцию:
numpy.array(object,
dtype=None, …)
Здесь в качестве
первого параметра object может выступать список или кортеж, а также функция или объект, возвращающий список или
кортеж. Второй параметр dtype – это тип элементов массива. Если
указано значение None, то тип будет определяться автоматически на основе
переданных данных. Подробнее об этой функции можно, как всегда, почитать на
странице официальной документации:
Итак, в самом
простом варианте можно создать одномерный массив так:
a = np.array(1, 2, 3, 4)
В результате
получим объект типа array с элементами 1, 2, 3, 4:
array()
Какой будет тип
у этих элементов? Мы можем его посмотреть с помощью атрибута dtype, выполнив в
консоли строчку:
a.dtype
Увидим:
dtype(‘int32’)
То есть,
автоматически был применен целочисленный тип размерностью 32 бит. Ну, хорошо, а
что если попробовать создать массив с разными типами его элементов, например,
так:
a = np.array(1, 2, "3", True)
В результате
увидим, следующее содержимое:
array(, dtype='<U11′)
Все элементы
стали строкового типа. Этот пример показывает, что в массивах NumPy используется
единый тип данных его элементов: или все целочисленные, или строковые, или
вещественные и так далее. Смешение типов в рамках одного массива не
допускается.
Отлично, это мы
сделали. Как теперь можно обращаться к отдельным элементам массива? Для этого
используется общий синтаксис:
<имя массива>
Например, для
нашего одномерного случая, мы можем взять первый элемент из массива a, следующим
образом:
a
Увидим значение ‘1’.
Обратите внимание, первый элемент имеет индекс 0, а не 1. Единица – это уже
второй элемент:
a1 # возвращает 2-й элемент со значением ‘2’
Для изменения
значения элемента, достаточно присвоить ему новое значение, например:
a1 = '123'
в результате
получим массив:
array(, dtype='<U11′)
А что будет,
если мы попробуем присвоить значение другого типа данных, например, число:
a1 = 234
Ошибки не будет,
а значение автоматически будет преобразовано в строку:
array(, dtype='<U11′)
Разработчики
пакета NumPy постарались
сделать его максимально дружественным, чтобы инженер сосредотачивался именно на
решении задачи, а не на нюансах программирования. Поэтому везде, там где это
допустимо, пакет NumPy берет на себя разрешение подобных
нюансов. И, как показала практика, это очень удобно и заметно облегчает жизнь
нам, простым смертным.
Параметры Numpy Random normal()
- loc: Это необязательный параметр. Входные данные подобны массиву или значению с плавающей запятой. Он определяет среднее значение распределения. По умолчанию он равен 0.0.
- scale: Это необязательный параметр. Входные данные подобны массиву или значению с плавающей запятой. Он определяет стандартное отклонение или плоскостность графика распределения, которая должна понравиться. По умолчанию он равен 1.0. Это не должно быть отрицательным значением.
- размер: Это необязательный параметр. Входные данные подобны целому числу или кортежу целых чисел. Он определяет форму результирующего массива. Если размер равен Нулю. По умолчанию он равен 1.
Python numpy nanmax
- In this section, we will discuss Python numpy nanmax.
- In this example, we can use the function numpy. nanmax().
- This function is used to returns the maximum value of an array or along any specifically mentioned axis of the array.
- An array with the same shape as arr, with the specific axis, is removed. If a is a 0-dimension numpy array, or if the axis is None, a numpy dimension array scalar is returned.
- The max value of a numpy array along a given axis, any NaNs.
Syntax:
Here is the Syntax of np. nanmax()
Example:
Here is the Screenshot of the following given code

Python numpy nanmax
Read Valueerror: Setting an array element with a sequence
Тест производительности
Мы не должны чередовать векторизованную операцию numpy вместе с циклом. Это резко снижает производительность, так как код повторяется с использованием собственного.
Например, в приведенном ниже фрагменте показано, как не следует использовать numpy.
for i in np.arange(100):
pass
Рекомендуемый способ – напрямую использовать операцию numpy.
np.arange(100)
Давайте проверим разницу в производительности с помощью модуля timeit.
import timeit
import numpy as np
# For smaller arrays
print('Array size: 1000')
# Time the average among 10000 iterations
print('range():', timeit.timeit('for i in range(1000): pass', number=10000))
print('np.arange():', timeit.timeit('np.arange(1000)', number=10000, setup='import numpy as np'))
# For large arrays
print('Array size: 1000000')
# Time the average among 10 iterations
print('range():', timeit.timeit('for i in range(1000000): pass', number=10))
print('np.arange():', timeit.timeit('np.arange(1000000)', number=10, setup='import numpy as np'))
Вывод:
Array size: 1000 range(): 0.18827421900095942 np.arange(): 0.015803234000486555 Array size: 1000000 range(): 0.22560399899884942 np.arange(): 0.011916546000065864
Как видите, numpy.arange() особенно хорошо работает для больших последовательностей. Это почти в 20 раз (!!) быстрее обычного кода Python для размера всего 1000000, который будет лучше масштабироваться только для больших массивов.
Следовательно, numpy.arange() должен быть единодушным выбором среди программистов при работе с большими массивами. Для небольших массивов, когда разница в производительности не так велика, вы можете использовать любой из двух методов.
Синтаксис
Давайте начнем с синтаксиса функции . Вот так он выглядит в общем виде:
Эта функция может принимать три аргумента. Первый и второй аргументы являются обязательными, а третий — опциональный.
Исходный массив NumPy, форму которого мы хотим изменить, – это значение первого аргумента ().
Форма массива устанавливается во втором аргументе (). Его значение может быть целым числом или кортежем целых чисел.
Значение третьего аргумента определяет порядок заполнения массива и переноса элементов в преобразованном массиве. Возможных значений три: «C», «F» или «A». Давайте разберем, что значит каждый из этих вариантов.
order=’C’
Упорядочивание индексов в стиле языка C. Индекс последней оси изменяется быстрее, а индекс первой — медленнее.
Упорядочение в стиле C. Источник
order=’F’
Упорядочивания индексов в стиле языка Фортран. Индекс первой оси изменяется быстрее, а индекс последней — медленнее.
Упорядочение в стиле Fortran
order=’A’
Варианты «C» и «F» не учитывают макет памяти основного массива. Они относятся лишь к порядку индексации. Порядок «A» означает чтение и запись элементов в стиле Фортран, если исходный массив в памяти тоже в стиле Фортран. В противном случае применяется C-подобный стиль.
Примеры функции Numpy Add
Давайте рассмотрим примеры функции Numpy add() и посмотрим, как она работает.
Пример 1: Использование Функции Np.add() Для сложения двух чисел
import numpy as np
print ("1st Input number : ", a1)
print ("2nd Input number : ", a2)
.add(a1, a2)
print ("Addition of two input number : ", ad)
Выход:
Объяснение
В этом простом первом примере мы просто добавили два числа и получили результат. Давайте посмотрим на каждый шаг и узнаем, что происходит на каждом этапе. Во-первых, мы импортировали модуль numpy как np это очевидно, потому что мы работаем над библиотекой numpy. После этого мы взяли два предопределенных входа ’24’, ’13’, и хранил их в переменных ‘a1’, ‘a2’ соответственно. Мы напечатали наши входные данные, чтобы проверить, правильно ли они указаны или нет. Затем идет основная часть, где мы найдем сложение между двумя числами.
Здесь с помощью функции np.add() мы рассчитаем сложение между a1 и a2. Эта операция сложения идентична тому, что мы делаем в математике.
Итак, мы получим сложение между числом 24 и 13, которое является 11.
Пример 2: Использование функции Np.add() для поиска сложения между двумя входными массивами
import numpy as np
a1 =
a2 =
print ("1st Input array : ", a1)
print ("2nd Input array : ", a2)
.add(a1, a2)
print ("Addition of two input arrays : ", ad)
Выход:
1st Input array : 2nd Input array : Addition of two input arrays :
Объяснение
Из этого примера все становится немного сложнее; вместо чисел мы использовали массивы в качестве нашего входного значения. Теперь мы можем видеть, что у нас есть два входных массива a1 и a2 с входами массива и , соответственно. Функция add() найдет добавление между аргументами массива a1 и a2 по элементам.
Таким образом, решение будет представлять собой массив с формой, равной входным массивам a1 и a2. Сложение между a1 и a2 будет вычисляться параллельно, и результат будет сохранен в переменной ad.
import numpy as np
a1 = , ]
a2 = , ]
print ("1st Input array : ", a1)
print ("2nd Input array : ", a2)
.add(a1, a2)
print ("Addition of two input arrays : ", ad)
Выход:
Объяснение
Третий пример в этом учебнике по функции add() немного похож на второй пример, который мы уже проходили. То, что мы сделали здесь в этом примере, – это вместо простого массива мы использовали многомерный массив в обоих наших входных значениях a1 и a2.
Убедитесь, что оба входных массива должны иметь одинаковый размер и одинаковую форму. Функция numpy.add() найдет добавление между href=”https://en.wikipedia.org/wiki/Array_data_structure”>массив аргументов , по элементам. href=”https://en.wikipedia.org/wiki/Array_data_structure”>массив аргументов , по элементам.
Pandas – удобство использования превыше всего
“Panel Data”, сокращено Pandas, на русский язык можно перевести как “Панельные данные”. Данный термин в эконометрии используется для набора данных, включающих многократные наблюдения за одними и теми же лицами.
В основе Pandas лежит класс DataFrame, предоставляющий возможности работы с двумерными массивами неоднотипных данных. Объект DataFrame составлен из объектов Series – одномерных массивов NumPy ndarray, объединенных под одним названием. Поэтому в DataFrame каждый столбец может иметь свой тип данных. На рисунке схематично показано архитектура DataFrame:

Представление DataFrame и Series
- чтение и запись данных, например, csv или excel таблица;
- группировку данных;
- средства визуализации данных;
- работу с датами;
- работу со строковыми значениями и т.д.
DataFrame
DataFrame – самая важная и широко используемая структура данных, а также стандартный способ хранения данных. Она содержит данные, выровненные по строкам и столбцам, как в таблице SQL или в базе данных электронной таблицы.
Мы можем либо жестко закодировать данные в DataFrame, либо импортировать файл CSV, файл tsv, файл Excel, таблицу SQL и т.д.
Мы можем использовать приведенный ниже конструктор для создания объекта DataFrame.
pandas.DataFrame(data, index, columns, dtype, copy)
Ниже приводится краткое описание параметров:
- data – создать объект DataFrame из входных данных. Это может быть список, dict, series, Numpy ndarrays или даже любой другой DataFrame;
- index – имеет метки строк;
- columns – используются для создания подписей столбцов;
- dtype – используется для указания типа данных каждого столбца, необязательный параметр;
- copy – используется для копирования данных, если есть.
Есть много способов создать DataFrame. Мы можем создать объект из словарей или списка словарей. Мы также можем создать его из списка кортежей, CSV, файла Excel и т.д.
Давайте запустим простой код для создания DataFrame из списка словарей.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ,
"Capital": ,
"Literacy %": ,
"Avg High Temp(c)":
})
print(df)
Вывод:

Первый шаг – создать словарь. Второй шаг – передать словарь в качестве аргумента в метод DataFrame(). Последний шаг – распечатать DataFrame.
Как видите, DataFrame можно сравнить с таблицей, имеющей неоднородное значение. Кроме того, можно изменить размер.
Мы предоставили данные в виде карты, и ключи карты рассматриваются Pandas, как метки строк.
Индекс отображается в крайнем левом столбце и имеет метки строк. Заголовок столбца и данные отображаются в виде таблицы.
Также возможно создавать индексированные DataFrames. Это можно сделать, настроив параметр индекса.
Основы метода Numpy arange()
В принципе, метод в модуле NumPy в Python используется для генерации линейной последовательности чисел на основе заранее заданных начальных и конечных точек вместе с постоянным размером шага.
Синтаксис,
import numpy as np np.arange( start , stop , step ,dtype=nome)
Здесь,
– это начальная точка будущей сгенерированной последовательности. Последовательность начинается с этого числа,
– это предел, до которого должна быть сгенерирована последовательность
Обратите внимание, что stop не включен в саму последовательность, только число до того, как оно будет рассмотрено
– это равномерный размер шага. По умолчанию, если в качестве шага ничего не передается, интерпретатор считает шаги равными единице(1)
Помните, что размер шага должен быть некоторым ненулевым значением, иначе возникнет .
– это тип результирующих элементов ndarray . По умолчанию он выводит тип из предоставленных параметров внутри метода. Тип может быть none, int или float и т. Д.
Пример Numpy arange()
Давайте разберемся в работе метода Numpy на примере:
import numpy as np
#passing start=1, stop=10, and step=2 and dtype=int
res=np.arange(1,10,2,int)
#printing the result
print("The resultant sequence is : ",res)
#analysing the type of the result
print("Type of returned result is:",type(res))
Вывод :
Здесь,
- Мы изначально импортировали модуль NumPy как для дальнейшего использования,
- Затем мы используем метод , передавая соответствующие аргументы start , stop , step и type как 1, 10, 2 и int для создания массива, состоящего из целых чисел от 1 до 9 с.
- Когда мы печатаем результирующую последовательность вместе с возвращаемого объекта, который оказывается членом класса .
Python numpy nan to zero
- In this method, we can easily use the function numpy.nan_to_num.
- Replacing NaN values with zeros in an array converts every Nan value to zero.
- We can easily use the np.nan_to_num method to convert numpy nan to zero.
- nan_to_num() function is used if we want to convert nan values with zero. It always returns positive infinity with the biggest number and negative infinity with the very smallest number.
Syntax:
- It consists of few parameters
- X: input data
- Copy: It is an optional parameter. Whether to create a copy of x or to exchange values in place. The in-place function only occurs if cast to an array that does not require the same array. The Default argument is True.
- Nan: Value to be used to fill Not a number values. If none of the values is passed through an array then NaN values will be replaced with 0.0.
- posinf: It is used to fill positive infinity values. If no value is passed then positive values will be exchanged with a large number.
Example:
- In the above code, we will import a numpy library and create an array by using the function numpy.array. Now create a variable and contains the values in the nan_to_num function.
- The output array will be displayed in the form of zero’s values and posinf values.
Here is the Screenshot of the following given code

Python numpy nan to zero
Read Python NumPy linspace
Можем Ли Мы Найти Сложение Между Двумя Массивами Numpy С Разными Формами?
Простыми словами, Нет, мы не можем найти сложение или использовать функцию numpy add в двух массивах numpy, которые имеют разные формы.
Давайте рассмотрим это на одном примере,
import numpy as np
a1 = , ]
a2 = , ]
print ("1st Input array : ", a1)
print ("2nd Input array : ", a2)
.add(a1, a2)
print ("Addition of two input arrays : ", ad)
Выход:
Объяснение
Если форма двух массивов numpy будет отличаться, то мы получим valueerror. Ошибка значения будет говорить что – то вроде, например.
ValueError: operands could not be broadcast together with shapes (2,3) (2,)
Здесь, в этом примере, мы получаем valueerror, потому что входной массив a2 имеет другую форму, чем входной массив a1. Чтобы получить сложение без какой-либо ошибки значения, обязательно проверьте форму массивов.
Параметры
- a : array_like – Это входной массив.
- q: array_like of float – Это процентиль или последовательность процентилей, которые нам нужно вычислить. Он должен быть от 0 до 100, оба включительно.
- axis: {int, кортеж int, None} – Это необязательный ввод. Это ось, по которой мы вычисляем процентиль. По умолчанию мы вычисляем процентиль вместе с уплощенной версией массива.
- out: ndarray – Это также необязательный вход. Это альтернативный выходной массив, который мы создаем для размещения результата. Он должен иметь ту же форму и длину буфера, что и ожидаемый вывод, но тип может быть приведен сам по себе, если это необходимо.
- overwrite_input: bool – Это также необязательный вход. Если логическое значение истинно, мы можем изменить входной массив с помощью промежуточных вычислений, чтобы сохранить память.
- keepdims: bool – Это также необязательный ввод. Если значение установлено равным True, то уменьшенные оси остаются в результате в виде размеров с одним размером. При этом результат будет корректно сопоставлен с исходным массивом.
Примеры работы с NumPy
Подытожим все вышесказанное. Вот несколько примеров полезных инструментов NumPy, которые могут значительно облегчить процесс написания кода.
Математические формулы NumPy
Необходимость внедрения математических формул, которые будут работать с матрицами и векторами, является главной причиной использования NumPy. Именно поэтому NumPy пользуется большой популярностью среди представителей науки. В качестве примера рассмотрим формулу , которая является центральной для контролируемых моделей машинного обучения, что решают проблемы регрессии:
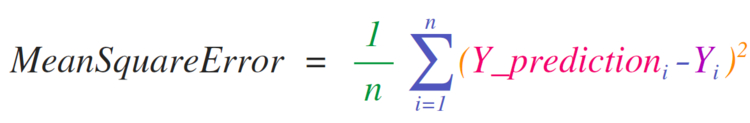
Реализовать данную формулу в NumPy довольно легко:

Главное достоинство NumPy в том, что его не заботит, если и содержат одно или тысячи значение (до тех пор, пока они оба одного размера). Рассмотрим пример, последовательно изучив четыре операции в следующей строке кода:

У обоих векторов и по три значения. Это значит, что в данном случае равно трем. После выполнения указанного выше вычитания мы получим значения, которые будут выглядеть следующим образом:

Затем мы можем возвести значения вектора в квадрат:

Теперь мы вычисляем эти значения:

Таким образом мы получаем значение ошибки некого прогноза и за качество модели.
Представление данных NumPy
Задумайтесь о всех тех типах данных, которыми вам понадобится оперировать, создавая различные модели работы (электронные таблицы, изображения, аудио и так далее). Очень многие типы могут быть представлены как n-мерные массивы:
Пример 4: Пример плитки Numpy в 2-D массиве
Достаточно примеров 1-D массива, в последнем примере мы будем работать с 2-D массивом. И как работать с этим типом массива.
Итак, перейдем непосредственно к примеру.
import numpy as np.array(, ]) reps = (2,2).tile(arr, reps) print(c)
Выход:
Объяснение
В приведенном выше примере мы сделали начальный шаг, аналогичный примерам 1, 2, 3. Но здесь вместо инициализации 1-D массива. Мы инициализировали 2-D массив со значениями , ]. После инициализации мы сохранили (2, 2) в ‘reps’ href=”https://en.wikipedia.org/wiki/Variable_(computer_science)#:~:text=In%20computer%20programming%2C%20a%20variable,referred%20to%20as%20a%20value.”>variable. Который будет нашим параметром повторения для функции np.tile (). После этого мы использовали эту функцию и выложили 2-d массив в соответствии с нашими требованиями. href=”https://en.wikipedia.org/wiki/Variable_(computer_science)#:~:text=In%20computer%20programming%2C%20a%20variable,referred%20to%20as%20a%20value.”>variable. Который будет нашим параметром повторения для функции np.tile (). После этого мы использовали эту функцию и выложили 2-d массив в соответствии с нашими требованиями.
Пример 2: Numpy Плитка Вертикально
В этом случае мы будем иметь простой 1-мерный вход и плитку вниз. В принципе, мы, скорее всего, будем смотреть на входную информацию так же, как на строку информации, и воспроизводить эту строку.
import numpy as np.array() reps = (3,1).tile(arr, reps) print(c)
Выход:
]
Объяснение:
В приведенном выше примере мы сначала импортировали модуль np. После этого, как и в примере 1, мы инициализировали и присвоили массив переменной ‘arr’. В этом примере мы добавили дополнительную строку ‘reps = (3,1)’. Здесь мы создаем плитку в вертикальном направлении. Итак, нам нужно сделать столбец матрицы равным 1. А для строки мы можем увеличить значение настолько, насколько это необходимо.
Итак, после форматирования строк и столбцов матрицы мы просто использовали функцию ‘np.tile()’. Как мы это сделали в примере 1. После этого мы просто напечатали возвращаемое значение и получили желаемый результат.
Сравнение numpy.arange() и range()
Весь смысл использования модуля numpy состоит в том, чтобы гарантировать, что выполняемые нами операции выполняются как можно быстрее, поскольку numpy – это интерфейс Python для кода C ++ нижнего уровня.
Многие операции в numpy векторизованы, что означает, что операции выполняются параллельно, когда numpy используется для выполнения любой математической операции. Благодаря этому для больших массивов и последовательностей numpy обеспечивает лучшую производительность.
Следовательно, numpy.arange() намного быстрее, чем собственная функция range() для генерации аналогичных линейных последовательностей.
7.3. Статистика
Над данными в массивах можно производить определенные вычисления, однако, не менее часто требуется эти данные как-то анализировать. Зачастую, в этом случае мы обращаемся к статистике, некоторые функции которой тоже имеются в NumPy. Данные функции могут применять как ко всем элементам массива, так и к элементам, расположенным вдоль определенной оси.
Элементарные статистические функции:
Средние значения элементов массива и их отклонения:
Корреляционные коэфициенты и ковариационные матрицы величин:
Так же NumPy предоставляет функции для вычисления гистограмм наборов данных различной размерности и некоторые другие статистичские функции.
Функции sum, mean, min и max
Итак, очень
часто на практике требуется вычислять сумму значений элементов массива, их
среднее значение, а также находить минимальные и максимальные значения. Для
этих целей в NumPy существуют
встроенные функции, выполняющие эти действия и сейчас мы посмотрим как они
работают. Пусть, как всегда, у нас имеется одномерный массив:
a = np.array( 1, 2, 3, 10, 20, 30)
Вычислим сумму,
среднее значение и найдем максимальное и минимальное значения:
a.sum() # 66 a.mean() # 11.0 a.max() # 30 a.min() # 1
Как видите, все
достаточно просто. Тот же самый результат будет получен и при использовании
многомерных массивов. Например:
a.resize(3, 2) a.sum() # 66
Но, если
требуется вычислить сумму только по какой-то одной оси, то ее можно явно
указать дополнительным параметром:
a.sum(axis=) # array() a.sum(axis=1) # array()
Точно также
работают и остальные три функции, например:
a.max(axis=) # array() a.min(axis=1) # array()