Изучение numpy с визуальными примерами для начинающих
Содержание:
- Добро пожаловать в NumPy!
- Установка NumPy
- Как импортировать NumPy
- В чем разница между списком Python и массивом NumPy?
- Что такое массив?
- Статистика¶
- Библиотека Numpy в Python
- Функции sum, mean, min и max
- Функции перемешивания элементов массива
- DataFrame
- Пример
- Фундаментальный элемент NumPy – массив (array)
- использованная литература
- Транспонирование и изменение формы матриц в numpy
- Почему SciPy?
- Минутка восхищения или что такого в массивах NumPy
- Массив Python
- Обработка текста в NumPy на примерах
- Создание десктопных приложений и UI
- Pandas – удобство использования превыше всего
- Matplotlib
- Синтаксис
Добро пожаловать в NumPy!
NumPy (NumericalPython) — это библиотека Python с открытым исходным кодом, которая используется практически во всех областях науки и техники. Это универсальный стандарт для работы с числовыми данными в Python, и он лежит в основе научных экосистем Python и PyData. В число пользователей NumPy входят все — от начинающих программистов до опытных исследователей, занимающихся самыми современными научными и промышленными исследованиями и разработками. API-интерфейс NumPy широко используется в пакетах Pandas, SciPy, Matplotlib, scikit-learn, scikit-image и в большинстве других научных и научных пакетов Python.
Библиотека NumPy содержит многомерный массив и матричные структуры данных (дополнительную информацию об этом вы найдете в следующих разделах). Он предоставляет ndarray, однородный объект n-мерного массива, с методами для эффективной работы с ним. NumPy может использоваться для выполнения самых разнообразных математических операций над массивами. Он добавляет мощные структуры данных в Python, которые гарантируют эффективные вычисления с массивами и матрицами, и предоставляет огромную библиотеку математических функций высокого уровня, которые работают с этими массивами и матрицами.
Узнайте больше о NumPy здесь!
GIF черезgiphy
Установка NumPy
Чтобы установить NumPy, я настоятельно рекомендую использовать научный дистрибутив Python. Если вам нужны полные инструкции по установке NumPy в вашей операционной системе, вы можетенайти все детали здесь,
Если у вас уже есть Python, вы можете установить NumPy с помощью
conda install numpy
или
pip install numpy
Если у вас еще нет Python, вы можете рассмотреть возможность использованияанаконда, Это самый простой способ начать. Преимущество этого дистрибутива в том, что вам не нужно слишком беспокоиться об отдельной установке NumPy или каких-либо основных пакетов, которые вы будете использовать для анализа данных, таких как pandas, Scikit-Learn и т. Д.
Если вам нужна более подробная информация об установке, вы можете найти всю информацию об установке наscipy.org,
фотоАдриеннотPexels
Если у вас возникли проблемы с установкой Anaconda, вы можете ознакомиться с этой статьей:
Как импортировать NumPy
Каждый раз, когда вы хотите использовать пакет или библиотеку в своем коде, вам сначала нужно сделать его доступным.
Чтобы начать использовать NumPy и все функции, доступные в NumPy, вам необходимо импортировать его. Это можно легко сделать с помощью этого оператора импорта:
import numpy as np
(Мы сокращаем «numpy» до «np», чтобы сэкономить время и сохранить стандартизированный код, чтобы любой, кто работает с вашим кодом, мог легко его понять и запустить.)
В чем разница между списком Python и массивом NumPy?
NumPy предоставляет вам огромный выбор быстрых и эффективных числовых опций. Хотя список Python может содержать разные типы данных в одном списке, все элементы в массиве NumPy должны быть однородными. Математические операции, которые должны выполняться над массивами, были бы невозможны, если бы они не были однородными.
Зачем использовать NumPy?
фотоPixabayотPexels
Массивы NumPy быстрее и компактнее, чем списки Python. Массив потребляет меньше памяти и намного удобнее в использовании. NumPy использует гораздо меньше памяти для хранения данных и предоставляет механизм задания типов данных, который позволяет оптимизировать код еще дальше.
Что такое массив?
Массив является центральной структурой данных библиотеки NumPy. Это таблица значений, которая содержит информацию о необработанных данных, о том, как найти элемент и как интерпретировать элемент. Он имеет сетку элементов, которые можно проиндексировать в Все элементы имеют одинаковый тип, называемыймассив dtype(тип данных).
Массив может быть проиндексирован набором неотрицательных целых чисел, логическими значениями, другим массивом или целыми числами.рангмассива это количество измерений.формамассива — это кортеж целых чисел, дающий размер массива по каждому измерению.
Одним из способов инициализации массивов NumPy является использование вложенных списков Python.
a = np.array(, , ])
Мы можем получить доступ к элементам в массиве, используя квадратные скобки. Когда вы получаете доступ к элементам, помните, чтоиндексирование в NumPy начинается с 0, Это означает, что если вы хотите получить доступ к первому элементу в вашем массиве, вы получите доступ к элементу «0».
print(a)
Выход:
Статистика¶
| Команда | Описание |
|---|---|
| amin(a) | минимум в массиве или минимумы вдоль одной из осей |
| amax(a) | максимум в массиве или максимумы вдоль одной из осей |
| nanmax(a) | максимум в массиве или максимумы вдоль одной из осей (игнорируются NaN). |
| nanmin(a) | минимум в массиве или минимумы вдоль одной из осей (игнорируются NaN). |
| ptp(a) | диапазон значений (максимум — минимум) вдоль оси |
| average(a) | взвешенное среднее вдоль оси |
| mean(a) | арифметическое среднее вдоль оси |
| median(a) | вычисление медианы вдоль оси |
| std(a) | стандартное отклонение вдоль оси |
| corrcoef(x) | коэффициенты корреляции |
| correlate(a, v) | кросс-корреляция двух одномерных последовательностей |
| cov(m) | ковариационная матрица для данных |
| histogram(a) | гистограмма из набора данных |
| histogram2d(x, y) | двумерная гистограмма для двух наборов данных |
| histogramdd(sample) | многомерная гистограмма для данных |
| bincount(x) | число появление значения в массиве неотрицательных значений |
| digitize(x, bins) | возвращает индексы интервалов к которым принадлежат элементы массива |
Библиотека Numpy в Python
Библиотека Numpy в Python широко используется для выполнения математических операций с матрицами
Наиболее важной особенностью Numpy, которая отличает его от других библиотек, является способность выполнять вычисления на молниеносной скорости. Это возможно благодаря C-API, который позволяет пользователю быстро получать результаты
Например, вы можете реализовать скалярное произведение двух матриц следующим образом:
Python
import numpy as np
mat1 = np.array(,])
mat2 = np.array(,])
np.dot(mat1,mat2)
|
1 2 3 4 5 6 |
importnumpy asnp mat1=np.array(1,2,3,4) mat2=np.array(5,6,7,8) np.dot(mat1,mat2) |
Результат:
Python
array(,
])
|
1 2 |
array(19,22, 43,50) |
Функции sum, mean, min и max
Итак, очень
часто на практике требуется вычислять сумму значений элементов массива, их
среднее значение, а также находить минимальные и максимальные значения. Для
этих целей в NumPy существуют
встроенные функции, выполняющие эти действия и сейчас мы посмотрим как они
работают. Пусть, как всегда, у нас имеется одномерный массив:
a = np.array( 1, 2, 3, 10, 20, 30)
Вычислим сумму,
среднее значение и найдем максимальное и минимальное значения:
a.sum() # 66 a.mean() # 11.0 a.max() # 30 a.min() # 1
Как видите, все
достаточно просто. Тот же самый результат будет получен и при использовании
многомерных массивов. Например:
a.resize(3, 2) a.sum() # 66
Но, если
требуется вычислить сумму только по какой-то одной оси, то ее можно явно
указать дополнительным параметром:
a.sum(axis=) # array() a.sum(axis=1) # array()
Точно также
работают и остальные три функции, например:
a.max(axis=) # array() a.min(axis=1) # array()
Функции перемешивания элементов массива
Следующие две
функции:
np.random.shuffle() и np.random.permutation()
перемешивают
случайным образом элементы массива. Например, дан массив:
a = np.arange(10) # array()
И нам требуется
перетасовать его элементы. В самом простом случае, это делается так:
np.random.shuffle(a) # array()
Причем, здесь
меняется сам массив a. Если вызвать эту функцию еще раз:
np.random.shuffle(a) # array()
то значения еще
раз перетасуются. Но, работает она только с первой осью axis0. Например,
если взять двумерный массив:
a = np.arange(1, 10).reshape(3, 3)
и вызвать эту
функцию:
np.random.shuffle(a)
то в массиве aбудут
переставлены только строки:
array(,
,
])
Вторая функция
возвращает случайную последовательность чисел, генерируя последовательность «на
лету»:
np.random.permutation(10) # array()
DataFrame
DataFrame – самая важная и широко используемая структура данных, а также стандартный способ хранения данных. Она содержит данные, выровненные по строкам и столбцам, как в таблице SQL или в базе данных электронной таблицы.
Мы можем либо жестко закодировать данные в DataFrame, либо импортировать файл CSV, файл tsv, файл Excel, таблицу SQL и т.д.
Мы можем использовать приведенный ниже конструктор для создания объекта DataFrame.
pandas.DataFrame(data, index, columns, dtype, copy)
Ниже приводится краткое описание параметров:
- data – создать объект DataFrame из входных данных. Это может быть список, dict, series, Numpy ndarrays или даже любой другой DataFrame;
- index – имеет метки строк;
- columns – используются для создания подписей столбцов;
- dtype – используется для указания типа данных каждого столбца, необязательный параметр;
- copy – используется для копирования данных, если есть.
Есть много способов создать DataFrame. Мы можем создать объект из словарей или списка словарей. Мы также можем создать его из списка кортежей, CSV, файла Excel и т.д.
Давайте запустим простой код для создания DataFrame из списка словарей.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ,
"Capital": ,
"Literacy %": ,
"Avg High Temp(c)":
})
print(df)
Вывод:

Первый шаг – создать словарь. Второй шаг – передать словарь в качестве аргумента в метод DataFrame(). Последний шаг – распечатать DataFrame.
Как видите, DataFrame можно сравнить с таблицей, имеющей неоднородное значение. Кроме того, можно изменить размер.
Мы предоставили данные в виде карты, и ключи карты рассматриваются Pandas, как метки строк.
Индекс отображается в крайнем левом столбце и имеет метки строк. Заголовок столбца и данные отображаются в виде таблицы.
Также возможно создавать индексированные DataFrames. Это можно сделать, настроив параметр индекса.
Пример
Давайте теперь объединим все это в простой пример, чтобы продемонстрировать линейность последовательностей, генерируемых numpy.arange().
Следующий код отображает 2 линейные последовательности между и с помощью numpy.arange(), чтобы показать, что последовательность генерирует единообразие, поэтому результирующие массивы являются линейными.
import numpy as np import matplotlib.pyplot as plt y = np.zeros(5) # Construct two linear sequences # First one has a step size of 4 units x1 = np.arange(0, 20, 4) # Second one has a step size of 2 units x2 = np.arange(0, 10, 2) # Plot (x1, ) plt.plot(x1, y, 'o') # Plot (x2, ) plt.plot(x2, y + 0.5, 'o') # Set limit for y on the plot plt.ylim() plt.show()
Вывод

Как вы можете видеть, оранжевые точки представляют линейную последовательность от 0 до 10 с размером шага 2 единицы, но поскольку 10 не включено, последовательность равна . Точно так же синие точки представляют последовательность .
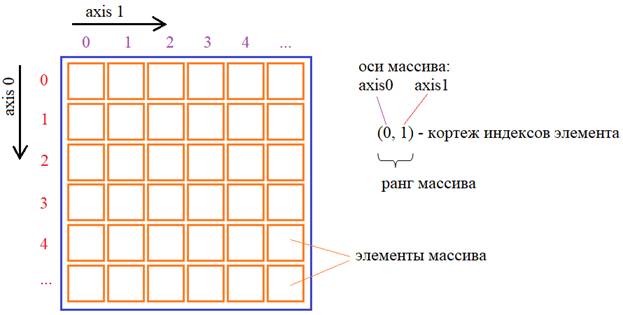
Фундаментальный элемент NumPy – массив (array)
Отлично,
сложнейший этап установки и импорта пакета позади. Пришло время сделать первые
шаги и вначале познакомиться с его фундаментальным элементом – однородным
многомерным массивом. В NumPy элементы массива имеют единый тип
данных. Их индексы описываются кортежем целых неотрицательных чисел.
Размерность кортежа – это ранг массива (то есть, размерность массива), а каждое
число в кортеже представляет свою отдельную ось:
Как создать
массив в NumPy? Существует много
способов, но базовый реализуется через функцию:
numpy.array(object,
dtype=None, …)
Здесь в качестве
первого параметра object может выступать список или кортеж, а также функция или объект, возвращающий список или
кортеж. Второй параметр dtype – это тип элементов массива. Если
указано значение None, то тип будет определяться автоматически на основе
переданных данных. Подробнее об этой функции можно, как всегда, почитать на
странице официальной документации:
Итак, в самом
простом варианте можно создать одномерный массив так:
a = np.array(1, 2, 3, 4)
В результате
получим объект типа array с элементами 1, 2, 3, 4:
array()
Какой будет тип
у этих элементов? Мы можем его посмотреть с помощью атрибута dtype, выполнив в
консоли строчку:
a.dtype
Увидим:
dtype(‘int32’)
То есть,
автоматически был применен целочисленный тип размерностью 32 бит. Ну, хорошо, а
что если попробовать создать массив с разными типами его элементов, например,
так:
a = np.array(1, 2, "3", True)
В результате
увидим, следующее содержимое:
array(, dtype='<U11′)
Все элементы
стали строкового типа. Этот пример показывает, что в массивах NumPy используется
единый тип данных его элементов: или все целочисленные, или строковые, или
вещественные и так далее. Смешение типов в рамках одного массива не
допускается.
Отлично, это мы
сделали. Как теперь можно обращаться к отдельным элементам массива? Для этого
используется общий синтаксис:
<имя массива>
Например, для
нашего одномерного случая, мы можем взять первый элемент из массива a, следующим
образом:
a
Увидим значение ‘1’.
Обратите внимание, первый элемент имеет индекс 0, а не 1. Единица – это уже
второй элемент:
a1 # возвращает 2-й элемент со значением ‘2’
Для изменения
значения элемента, достаточно присвоить ему новое значение, например:
a1 = '123'
в результате
получим массив:
array(, dtype='<U11′)
А что будет,
если мы попробуем присвоить значение другого типа данных, например, число:
a1 = 234
Ошибки не будет,
а значение автоматически будет преобразовано в строку:
array(, dtype='<U11′)
Разработчики
пакета NumPy постарались
сделать его максимально дружественным, чтобы инженер сосредотачивался именно на
решении задачи, а не на нюансах программирования. Поэтому везде, там где это
допустимо, пакет NumPy берет на себя разрешение подобных
нюансов. И, как показала практика, это очень удобно и заметно облегчает жизнь
нам, простым смертным.
использованная литература
Работая в качестве исследователя в распределенных системах, доктор Кристиан Майер нашел свою любовь к учению студентов компьютерных наук.
Чтобы помочь студентам достичь более высоких уровней успеха Python, он основал сайт программирования образования Finxter.com Отказ Он автор популярной книги программирования Python One-listers (Nostarch 2020), Coauthor of Кофе-брейк Python Серия самооставленных книг, энтузиаста компьютерных наук, Фрилансера и владелец одного из лучших 10 крупнейших Питон блоги по всему миру.
Его страсти пишут, чтение и кодирование. Но его величайшая страсть состоит в том, чтобы служить стремлению кодер через Finxter и помогать им повысить свои навыки. Вы можете присоединиться к его бесплатной академии электронной почты здесь.
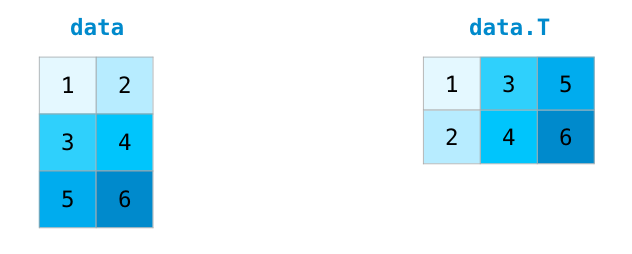
Транспонирование и изменение формы матриц в numpy
Нередки случаи, когда нужно повернуть матрицу. Это может потребоваться при вычислении скалярного произведения двух матриц. Тогда возникает необходимость наличия совпадающих размерностей. У массивов NumPy есть полезное свойство под названием , что отвечает за транспонирование матрицы.
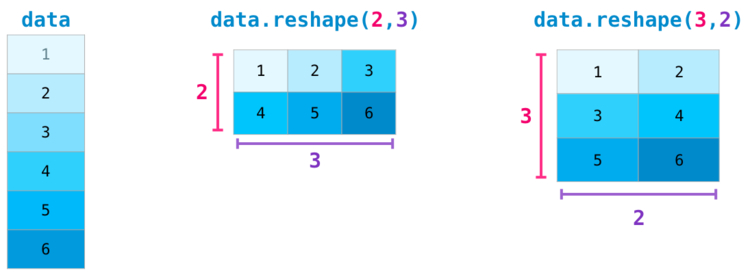
Некоторые более сложные ситуации требуют возможности переключения между размерностями рассматриваемой матрицы. Это типично для приложений с машинным обучением, где некая модель может запросить определенную форму вывода, которая является отличной от формы начального набора данных. В таких ситуациях пригодится метод из NumPy. Здесь от вас требуется только передать новые размерности для матрицы. Для размерности вы можете передать , и NumPy выведет ее верное значение, опираясь на данные рассматриваемой матрицы:
Еще больше размерностей NumPy
NumPy может произвести все вышеперечисленные операции для любого количества размерностей. Структура данных, расположенных центрально, называется , или n-мерным массивом.

В большинстве случаев для указания новой размерности требуется просто добавить запятую к параметрам функции NumPy:
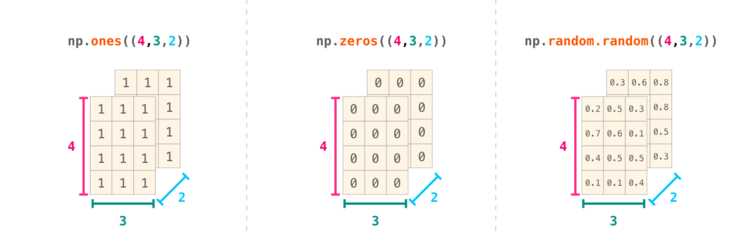
Shell
array(,
,
],
,
,
],
,
,
],
,
,
]])
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
array(1.,1., 1.,1., 1.,1., 1.,1., 1.,1., 1.,1., 1.,1., 1.,1., 1.,1., 1.,1., 1.,1., 1.,1.) |
Почему SciPy?
SciPy предоставляет высокоуровневые команды и классы для управления данными и визуализации данных, что значительно увеличивает мощность интерактивного сеанса Python.
Помимо математических алгоритмов в SciPy, программисту доступно все, от классов, веб-подпрограмм и баз данных до параллельного программирования, что упрощает и ускоряет разработку сложных и специализированных приложений.
Поскольку SciPy имеет открытый исходный код, разработчики по всему миру могут вносить свой вклад в разработку дополнительных модулей, что очень полезно для научных приложений, использующих SciPy.
Минутка восхищения или что такого в массивах NumPy
Но, все-таки,
что такого в массивах NumPy, что они повсеместно используются в
разных библиотеках? Давайте я приведу несколько примеров, и вы сами все
увидите.
Предположим, мы
определили одномерный массив с числами от 1 до 9:
a = np.array(1,2,3,4,5,6,7,8,9)
Мы уже знаем как
взять один отдельный элемент, но что будет, если прописать индексы для всех 9
элементов:
a 1,1,1,1,1,1,1,1,1
На выходе увидим
одномерный массив из двоек:
array()
Или, так:
a 1,1,1,1,1
тогда получим
аналогичный массив, но размерностью 5 элементов:
array()
Как видите,
индексирование здесь более гибкое, чем у обычных списков Python. Или, вот еще один характерный пример:
a True, True, False, False, False, False, True, True, True
Результат будет
следующим:
array()
То есть,
остаются элементы со значениями True и отбрасываются со значениями False. Обо всем этом
мы еще будем подробно говорить.
Еще один пример.
Предположим, нам понадобилось представить одномерный массив a в виде матрицы
3х3. Нет ничего проще, меняем его размерность:
b = a.reshape(3, 3)
и получаем
заветный результат:
array(,
,
])
Далее, можем
обращаться к элементам матрицы b так:
b12
или так:
b1, 2
В обоих случаях
будет взят один и тот же элемент со значением 6.
Все это лишь
мимолетный взгляд на возможности пакета NumPy. Я здесь лишь
хотел показать, насколько сильно отличаются массивы array от списков
языка Python, и если вы
хотите овладеть этим инструментом, то эта серия занятий для вас.
Видео по теме
#1. Пакет numpy — установка и первое знакомство | NumPy уроки
#2. Основные типы данных. Создание массивов функцией array() | NumPy уроки
#3. Функции автозаполнения, создания матриц и числовых диапазонов | NumPy уроки
#4. Свойства и представления массивов, создание их копий | NumPy уроки
#5. Изменение формы массивов, добавление и удаление осей | NumPy уроки
#6. Объединение и разделение массивов | NumPy уроки
#7. Индексация, срезы, итерирование массивов | NumPy уроки
#8. Базовые математические операции над массивами | NumPy уроки
#9. Булевы операции и функции, значения inf и nan | NumPy уроки
#10. Базовые математические функции | NumPy уроки
#11. Произведение матриц и векторов, элементы линейной алгебры | NumPy уроки
#12. Множества (unique) и операции над ними | NumPy уроки
#13. Транслирование массивов | NumPy уроки
Массив Python
Python поддерживает все операции, связанные с массивом через объект своего списка. Начнем с одномерного инициализации массива.
Пример массива Python
Элементы массива Python определены в скобках И они разлучены запятыми. Ниже приведен пример объявления одномерного массива Python.
arr = print (arr) print (arr) print (arr)
Выход из двухмерного массива пример программы будет:
3 5
Индексирование массива начинается от 0. Таким образом, значение индекса 2 переменной ARR составляет 3.
В некоторых других языках программирования, такие как Java, когда мы определяем массив, нам также нужно определить тип элемента, поэтому мы ограничиваем хранение только в том виде данных в массиве. Например, умеет хранить только целые данные.
Но Python дает нам гибкость иметь различные данные данных в том же массиве. Это круто, верно? Давайте посмотрим пример.
student_marks = marks = student_marks+student_marks print(student_marks + ' has got in total = %d + %f = %f ' % (student_marks, student_marks, marks ))
Он дает следующий выход:
Akkas has got in total = 45 + 36.500000 = 81.500000 marks
В приведенном выше примере вы можете увидеть это, Массив имеют три типа данных – строка, int и float.
Python многомерный массив
Двухмерный массив в Python может быть объявлен следующим образом.
arr2d = , ] print(arr2d) # prints elements of row 0 print(arr2d) # prints elements of row 1 print(arr2d) # prints element of row = 1, column = 1
Это даст следующий вывод:
4
Точно так же мы можем определить трехмерный массив или многомерный массив в Python.
Примеры массива Python
Теперь, когда мы знаем, как определить и инициализировать массив в Python. Мы рассмотрим разные операции, которые мы можем выполнить на массиве Python.
Массив Python, проходящая с использованием для петли
Мы можем использовать для петли для прохождения сквозь элементы массива. Ниже приведен простой пример для цикла для прохождения через массив.
arrayElement = for i in range(len(arrayElement)): print(arrayElement)
Ниже изображения показывает вывод, создаваемый вышеупомянутым примером примера массива.
Пересекающий 2D-массив, используя для петли
Следующий код распечатает элементы ROW-WISE, а затем следующая часть печатает каждый элемент данного массива.
arrayElement2D = , ]
for i in range(len(arrayElement2D)):
print(arrayElement2D)
for i in range(len(arrayElement2D)):
for j in range(len(arrayElement2D)):
print(arrayElement2D)
Это выведет:
Python Array Append
arrayElement =
arrayElement.append('Four')
arrayElement.append('Five')
for i in range(len(arrayElement)):
print(arrayElement)
Новый элемент четыре и пять будут добавлены в конце массива.
One 2 Three Four Five
Вы также можете добавить массив на другой массив. Следующий код показывает, как вы можете сделать это.
arrayElement = newArray = arrayElement.append(newArray); print(arrayElement)
]
Теперь наш одномерный массив наращивания превращается в многомерное массив.
Массив Python размер
Мы можем использовать Функция для определения размера массива. Давайте посмотрим на простой пример для длины массива Python.
arr = arr2d = ,] print(len(arr)) print(len(arr2d)) print(len(arr2d)) print(len(arr2d))
Нарезание массива Python
Python предоставляет особый способ создания массива из другого массива, используя нотацию среза. Давайте посмотрим на несколько примеров ломтиков наращиваний Python.
arr = #python array slice arr1 = arr #start to index 2 print(arr1) arr1 = arr #index 2 to end of arr print(arr1) arr1 = arr #start to index 2 print(arr1) arr1 = arr #copy of whole arr print(arr1) arr1 = arr # from index 1 to index 5 with step 2 print(arr1)
Ниже приведены изображение Python Array Slice Program Example.
Мы можем вставить элемент в массиве, используя функция.
arr = arr.insert(3,10) print(arr)
Python Array POP.
Мы можем вызвать функцию POP на массиве, чтобы удалить элемент из массива по указанному индексу.
arr = arr.insert(3,10) print(arr) arr.pop(3) print(arr)
Это все о массиве Python и разных операций, которые мы можем выполнить для массивов в Python.
Обработка текста в NumPy на примерах
Когда дело доходит до текста, подход несколько меняется. Цифровое представление текста предполагает создание некого , то есть инвентаря всех уникальных слов, которые бы распознавались моделью, а также векторно (embedding step). Попробуем представить в цифровой форме цитату из стихотворения арабского поэта Антара ибн Шаддада, переведенную на английский язык:
“Have the bards who preceded me left any theme unsung?”
Перед переводом данного предложения в нужную цифровую форму модель должна будет проанализировать огромное количество текста. Здесь можно обработать небольшой набор данный, после чего использовать его для создания словаря из 71 290 слов.

Предложение может быть разбито на массив токенов, что будут словами или частями слов в зависимости от установленных общих правил:

Затем в данной таблице словаря вместо каждого слова мы ставим его :

Однако данные все еще не обладают достаточным количеством информации о модели как таковой. Поэтому перед передачей последовательности слов в модель токены/слова должны быть заменены их векторными представлениями. В данном случае используется 50-мерное векторное представление Word2vec.

Здесь ясно видно, что у массива NumPy есть несколько размерностей . На практике все выглядит несколько иначе, однако данное визуальное представление более понятно для разъяснения общих принципов работы.
Для лучшей производительности модели глубокого обучения обычно сохраняют первую размерность для пакета. Это происходит из-за того, что тренировка модели происходит быстрее, если несколько примеров проходят тренировку параллельно. Здесь особенно полезным будет . Например, такая модель, как BERT, будет ожидать ввода в форме: .
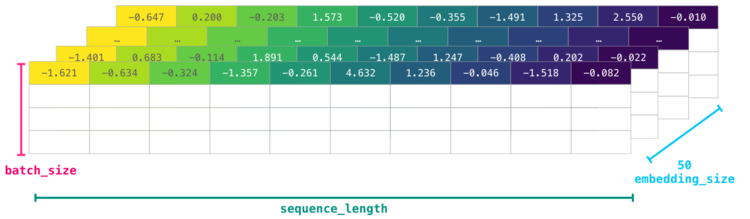
Теперь мы получили числовой том, с которым модель может работать и делать полезные вещи. Некоторые строки остались пустыми, однако они могут быть заполнены другими примерами, на которых модель может тренироваться или делать прогнозы.
(На заметку: Поэма, строчку из которой мы использовали в примере, увековечила своего автора в веках. Будучи незаконнорожденным сыном главы племени от рабыни, Антара ибн Шаддан мастерски владел языком поэзии. Вокруг исторической фигуры поэта сложились мифы и легенды, а его стихи стали частью классической арабской литературы).
Создание десктопных приложений и UI
EEL
Для работы с созданием графических приложений есть несколько популярных библиотек, в частности встроенный tkinter и Qt. Но когда необходимо сделать красивое, легковесное графическое приложение, то хотелось бы использовать что-то более мощное, например, html+css+js, именно с этим может помочь библиотека EEL. Она позволяет создать десктопное приложение, где в качестве графической оболочки используется html, css и js (можно использовать различные фреймворки), а в качестве языка для написания бэк-части используется Python (подробнее тут).
Приведем простой пример использования библиотеки. Python код:
Файл index.html:
И сама структура проекта должна выглядеть так:
Можно запустить файл main.py и убедиться, что всё работает:
Pandas – удобство использования превыше всего
“Panel Data”, сокращено Pandas, на русский язык можно перевести как “Панельные данные”. Данный термин в эконометрии используется для набора данных, включающих многократные наблюдения за одними и теми же лицами.
В основе Pandas лежит класс DataFrame, предоставляющий возможности работы с двумерными массивами неоднотипных данных. Объект DataFrame составлен из объектов Series – одномерных массивов NumPy ndarray, объединенных под одним названием. Поэтому в DataFrame каждый столбец может иметь свой тип данных. На рисунке схематично показано архитектура DataFrame:

Представление DataFrame и Series
- чтение и запись данных, например, csv или excel таблица;
- группировку данных;
- средства визуализации данных;
- работу с датами;
- работу со строковыми значениями и т.д.
Matplotlib
Matplotlib имеет мощную и при этом еще и красивую визуализацию. Она представляет собой библиотеку построения графиков для Python с 26000 коммитами на GitHub и активным сообществом примерно из 700 участников. Благодаря графикам и чертежам, которые умеет выводить Matplotlib, она широко используется для визуализации данных. Matplotlib также предоставляет объектно-ориентированный API, который можно использовать для встраивания графиков в различные приложения.
Особенности:
- Может использоваться в качестве бесплатной альтернативы MATLAB, с открытым исходным кодом.
- Поддерживает десятки подчиненных приложений и типов данных для вывода, что означает, что вы можете пользоваться Matplotlib вне зависимости от того какая у вас операционная система и какой формат вы предпочитаете.
- Pandas может быть использована в качестве оболочки для Matplotlib API для управления Matplotlib, в качестве фильтра.
- Низкое потребление памяти и хорошая работа во время выполнения.
Области использования:
- Корреляционный анализ переменных.
- Визуализация интервалов 95-процентной вероятности для моделей.
- Обнаружение выделяющихся значений с использованием точечной диаграммы и т. п.
- Визуализация распределения данных для получения реальной картины
Видео Top 5 Python Libraries for Data Science демонстрирует простые примеры, которые помогут получить общее представление о возможностях Matplotlib.
Наряду с этими библиотеками специалисты Data Science также используют возможности некоторых других полезных библиотек:
Подобно TensorFlow, Keras — является еще одной популярной библиотекой, которая широко используется для модулей глубокого обучения и нейронных сетей. Keras поддерживает в качестве подчиненного приложения как TensorFlow, так и Theano, поэтому представляет собой хороший вариант, если вы не хотите погружаться в детали TensorFlow.
Scikit-learn — это библиотека машинного обучения, которая предоставляет практически все необходимые алгоритмы машинного обучения. Scikit-learn предназначен для совместной работы с NumPy и SciPy.
Seabourn — еще одна библиотека для визуализации данных. Это расширение matplotlib, предоставляющее дополнительные типы графиков.
Вот видео Simplilearn, в котором рассматриваются 5 лучших библиотек Python для Data Science, созданное экспертами в этой области.
В дополнение к пяти наиболее популярным библиотекам Python и трем другим полезным библиотекам, которые здесь обсуждались, есть много других не менее ценных библиотек для Data Science, заслуживающих вашего внимания. О них вы сможете прочитать в наших следующих статьях.
Скачать
×
Синтаксис
Давайте начнем с синтаксиса функции . Вот так он выглядит в общем виде:
Эта функция может принимать три аргумента. Первый и второй аргументы являются обязательными, а третий — опциональный.
Исходный массив NumPy, форму которого мы хотим изменить, – это значение первого аргумента ().
Форма массива устанавливается во втором аргументе (). Его значение может быть целым числом или кортежем целых чисел.
Значение третьего аргумента определяет порядок заполнения массива и переноса элементов в преобразованном массиве. Возможных значений три: «C», «F» или «A». Давайте разберем, что значит каждый из этих вариантов.
order=’C’
Упорядочивание индексов в стиле языка C. Индекс последней оси изменяется быстрее, а индекс первой — медленнее.
Упорядочение в стиле C. Источник
order=’F’
Упорядочивания индексов в стиле языка Фортран. Индекс первой оси изменяется быстрее, а индекс последней — медленнее.
Упорядочение в стиле Fortran
order=’A’
Варианты «C» и «F» не учитывают макет памяти основного массива. Они относятся лишь к порядку индексации. Порядок «A» означает чтение и запись элементов в стиле Фортран, если исходный массив в памяти тоже в стиле Фортран. В противном случае применяется C-подобный стиль.