Screaming frog seo spider 15.2 + key
Содержание:
- Small Update – Version 14.1 Released 7th December 2021
- Сканирование списка URL-адресов для переадресации
- Small Update – Version 10.2 Released 3rd October 2018
- 1) Configurable Database Storage (Scale)
- Small Update – Version 9.3 Released 29th May 2018
- Загрузка списка
- 1) Scheduling
- Small Update – Version 4.1 Released 16th July 2015
- 6) Post Crawl Analysis
- Small Update – Version 13.1 Released 15th July 2020
- Small Update – Version 14.2 Released 16th February 2021
- Small Update – Version 3.3 Released 23rd March 2015
- Understanding Bot Behaviour with the Log File Analyzer
- Small Update – Version 12.4 Released 18th December 2019
- 5) Агрегированная структура сайта
- Other Updates
- Troubleshooting
- 10) Improved Redirect & Canonical Chain Reports
- Crawl Overview Report
Small Update – Version 14.1 Released 7th December 2021
We have just released a small update to version 14.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix ‘Application Not Responding’ issue which affected a small number of users on Windows.
- Maintain Google Sheets ID when overwriting.
- Improved messaging in Force-Directed Crawl Diagram scaling configuration, when scaling on items that are not enabled (GA etc).
- Removed .xml URLs from appearing in the ‘Non-Indexable URLs in Sitemap’ filter.
- Increase the size of Custom Extraction text pop-out.
- Allow file name based on browse selection in location chooser.
- Add AMP HTML column to internal tab.
- Fix crash in JavaScript crawling.
- Fix crash when selecting ‘View in Internal Tab Tree View’ in the the Site Structure tab.
- Fix crash in image preview details window.
Сканирование списка URL-адресов для переадресации
Наконец, если у вас есть список URL-адресов, для которых вы хотели бы проверять перенаправления вместо сканирования веб-сайта, вы можете загрузить их в .
Чтобы переключиться в режим «список», просто нажмите «режим> список» на верхнем уровне навигации, и тогда вы сможете выбрать вставку URL-адресов, их ввод вручную или загрузку через файл.
При массовой загрузке URL-адресов мы рекомендуем внимательно прочитать наше руководство «Как проверять перенаправления с помощью SEO Spider ». Это руководство содержит более подробную информацию о том, как правильно настроить SEO Spider, чтобы он следовал по ссылкам до конечного пункта назначения и отображал все это в одном отчете.
Надеюсь, приведенное выше руководство поможет проиллюстрировать, как использовать инструмент SEO Spider в качестве средства проверки массового перенаправления.
Пожалуйста, также прочтите наши ответы на часто задаваемые вопросы о Screaming Frog SEO spider и полное руководство пользователя для получения дополнительной информации.
Источник записи: https://www.screamingfrog.co.uk
Small Update – Version 10.2 Released 3rd October 2018
We have just released a small update to version 10.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- –headless can now be run on Ubuntu under Windows.
- Added configuration option “Respect Self Referencing Meta Refresh” (Configuration > Spider > Advanced). Lots of websites have self-referencing meta refereshes, which can be classed as ‘non-indexable’, and this can now simply be switched off.
- URLs added to the crawl via GA/GSC now got through URL rewriting and exclude configuration.
- Various scheduling fixes.
- The embedded browser now runs in a sandbox.
- The Force-Directed Diagram directory tree now considers non-trailing slash URLs as potential directories, and doesn’t duplicate where appropriate.
- Fix bug with ‘Custom > Extraction’ filter missing columns when run headless.
- Fix issue preventing crawls saving with more than 32k of custom extraction data.
- Fix issue with ‘Link Score’ not being saved/restored.
- Fix crash when accessing the Forms Based Authentiction.
- Fix crash when uploading duplicate SERP URLs.
- Fix crashes introduced by update to macOS 10.14 Mojave.
1) Configurable Database Storage (Scale)
The SEO Spider has traditionally used RAM to store data, which has enabled it to have some amazing advantages; helping to make it lightning fast, super flexible, and providing real-time data and reporting, filtering, sorting and search, during crawls.
However, storing data in memory also has downsides, notably crawling at scale. This is why version 9.0 now allows users to choose to save to disk in a database, which enables the SEO Spider to crawl at truly unprecedented scale for any desktop application while retaining the same, familiar real-time reporting and usability.
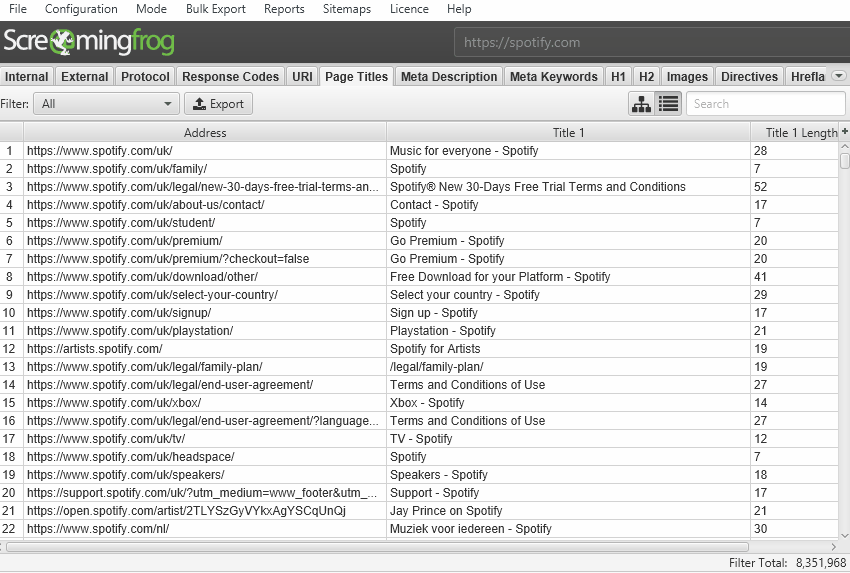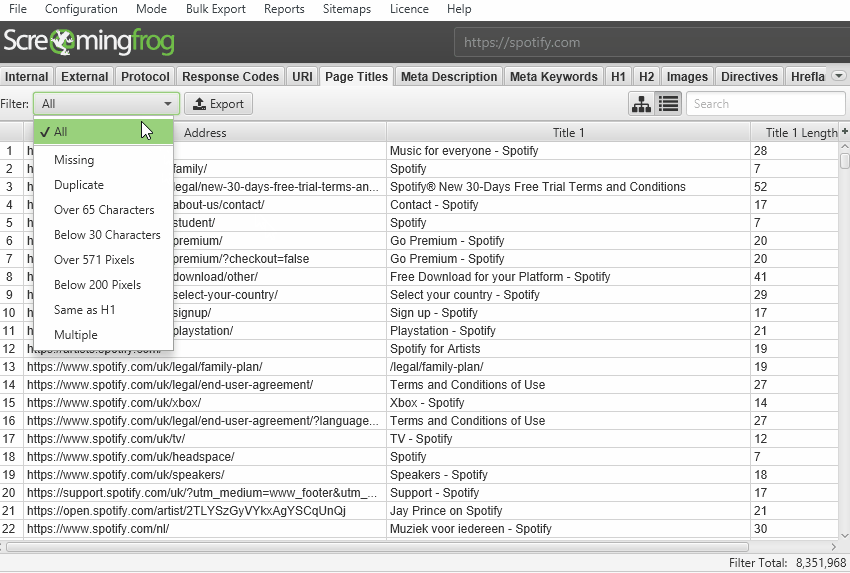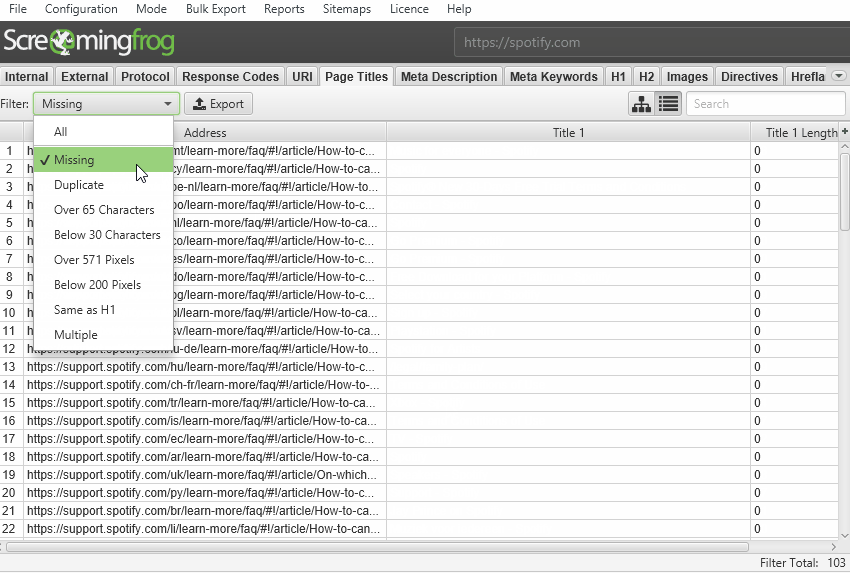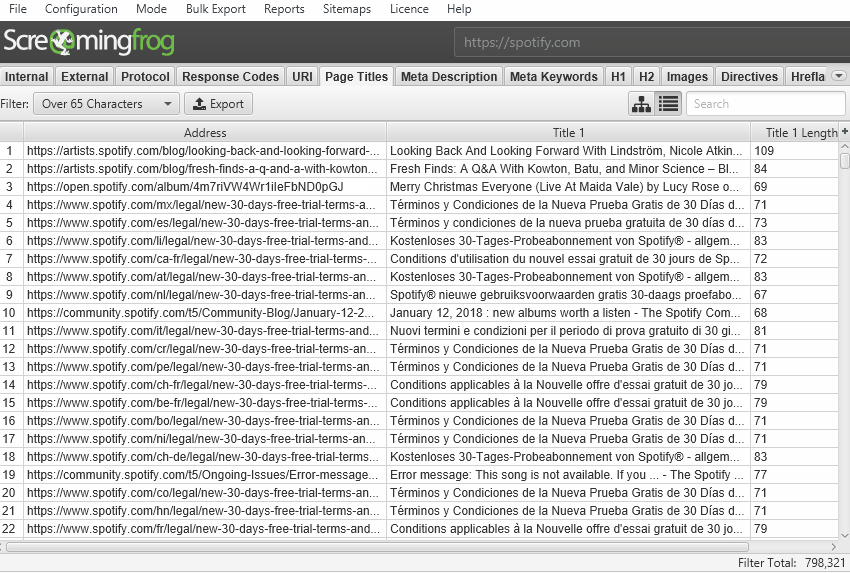
The default crawl limit is now set at 5 million URLs in the SEO Spider, but it isn’t a hard limit, the SEO Spider is capable of crawling significantly more (with the right hardware). Here are 10 million URLs crawled, of 26 million (with 15 million sat in the queue) for example.
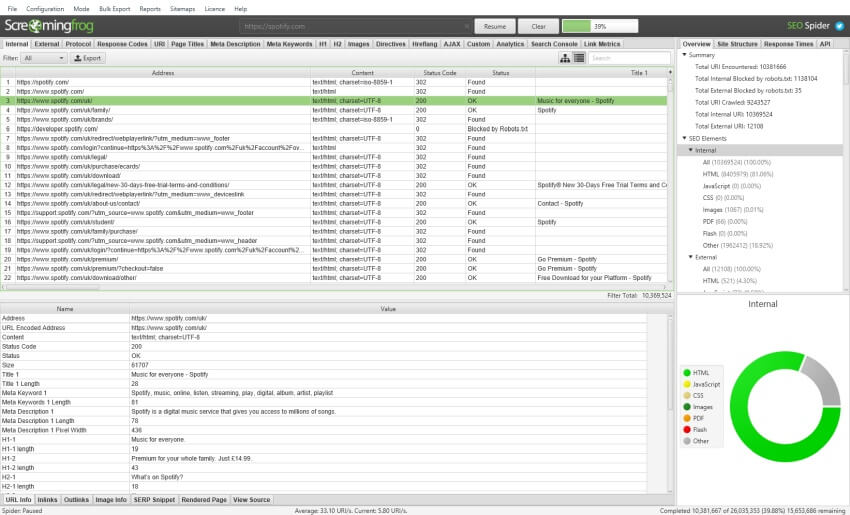
We have a hate for pagination, so we made sure the SEO Spider is powerful enough to allow users to view data seamlessly still. For example, you can scroll through 8 million page titles, as if it was 800.
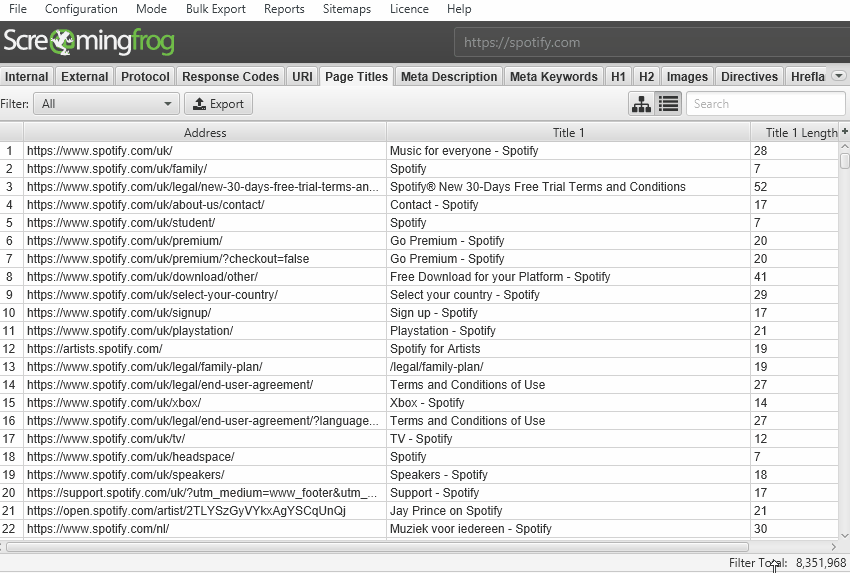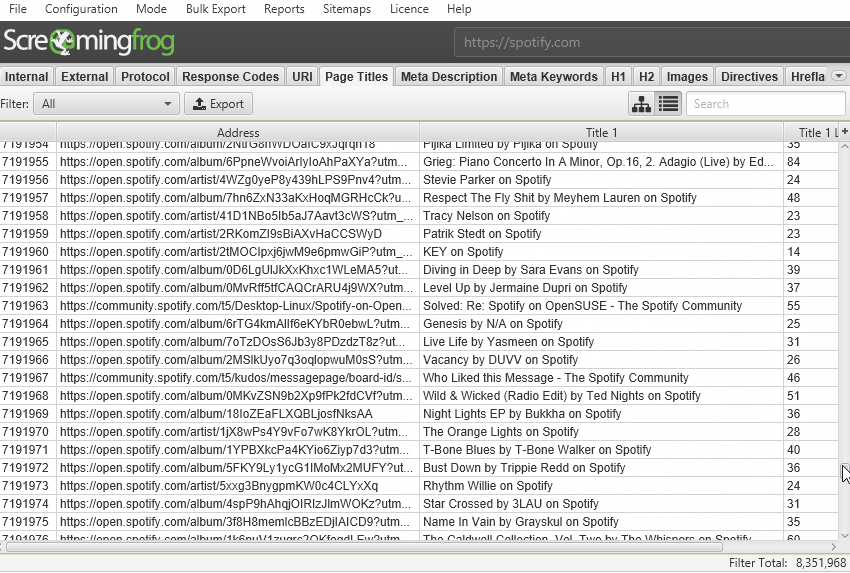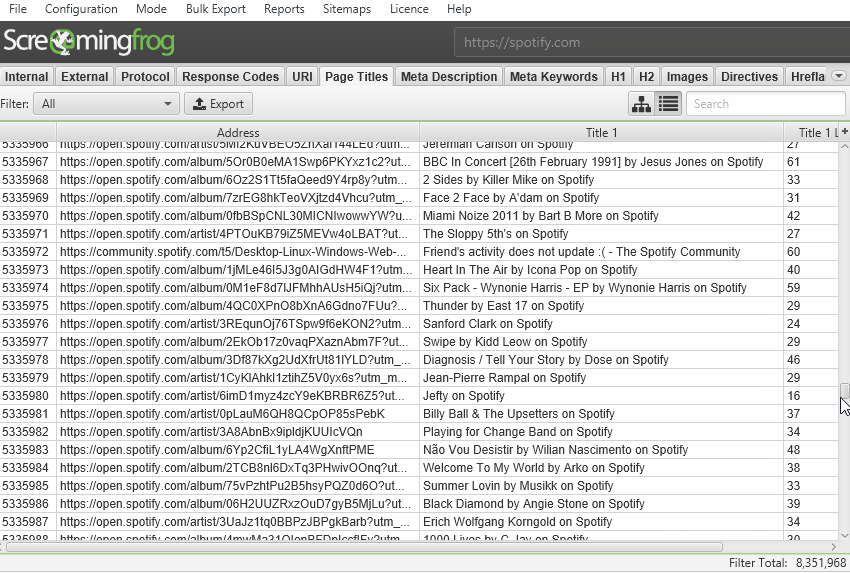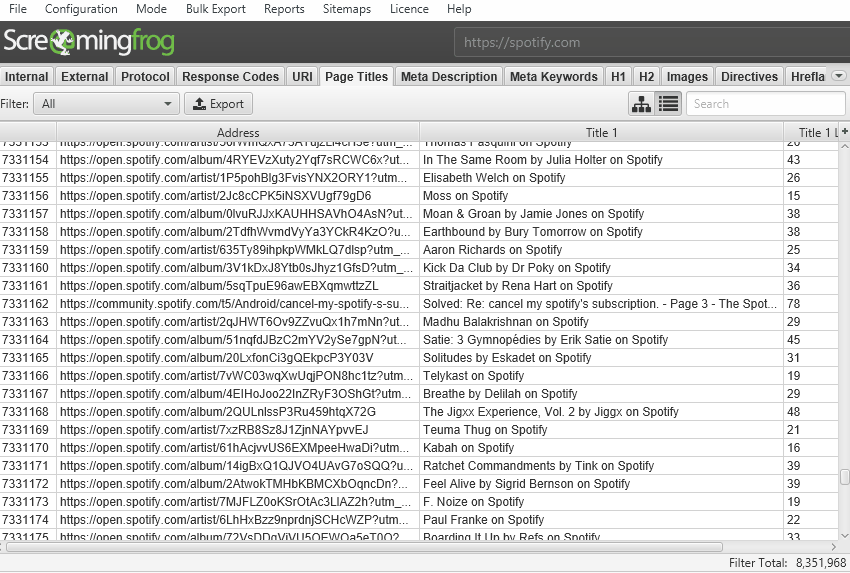
The reporting and filters are all instant as well, although sorting and searching at huge scale will take some time.
It’s important to remember that crawling remains a memory intensive process regardless of how data is stored. If data isn’t stored in RAM, then plenty of disk space will be required, with adequate RAM and ideally SSDs. So fairly powerful machines are still required, otherwise crawl speeds will be slower compared to RAM, as the bottleneck becomes the writing speed to disk. SSDs allow the SEO Spider to crawl at close to RAM speed and read the data instantly, even at huge scale.
By default, the SEO Spider will store data in RAM (‘memory storage mode’), but users can select to save to disk instead by choosing ‘database storage mode’, within the interface (via ‘Configuration > System > Storage), based upon their machine specifications and crawl requirements.
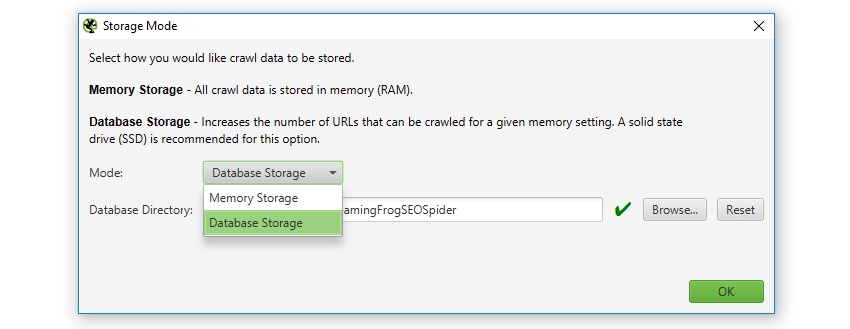
Users without an SSD, or are low on disk space and have lots of RAM, may prefer to continue to crawl in memory storage mode. While other users with SSDs might have a preference to just crawl using ‘database storage mode’ by default. The configurable storage allows users to dictate their experience, as both storage modes have advantages and disadvantages, depending on machine specifications and scenario.
Please see our guide on how to crawl very large websites for more detail on both storage modes.
The saved crawl format (.seospider files) are the same in both storage modes, so you are able to start a crawl in RAM, save, and resume the crawl at scale while saving to disk (and vice versa).
Small Update – Version 9.3 Released 29th May 2018
We have just released a small update to version 9.3 of the SEO Spider. Similar to 9.1 and 9.2, this release addresses bugs and includes some small improvements as well.
- Update SERP snippet pixel widths.
- Update to Java 1.8 update 171.
- Shortcuts not created for user account when installing as admin on Windows.
- Can’t continue with Majestic if you load a saved crawl.
- Removed URL reappears after crawl save/load.
- Inlinks vanish after a re-spider.
- External inlinks counts never updated.
- HTTP Canonicals wrong when target url contains a comma.
- Exporting ‘Directives > Next/Prev’ fails due to forward slash in default file name.
- Crash when editing SERP description using Database Storage Mode.
- Crash in AHREFs when crawling with no credits.
- Crash on startup caused by user installed java libraries.
- Crash removing URLs in tree view.
- Crash crawling pages with utf-7 charset.
- Crash using Datebase Storage Mode in a Turkish Locale.
- Loading of corrupt .seospider file causes crash in Database Storage Mode.
- Missing dependencies when initializing embedded browser on ubuntu 18.04.
Загрузка списка
Когда вы находитесь в режиме списка (Режим> Список), просто нажмите кнопку «Загрузить» и выберите загрузку из файла, войдите в диалоговое окно, вставьте список URL-адресов или загрузите XML-карту сайта.
Это так просто. Но есть пара вещей, о которых вам следует знать в режиме списка при загрузке URL-адресов.
Требуется протокол
Если вы не включите ни HTTP, ни HTTPS (например, просто www.screamingfrog.co.uk/), URL-адрес не будет прочитан и выгружен.
Вы увидите очень печальное сообщение «найдено 0 URL-адресов». Поэтому всегда включайте URL-адрес с протоколом, например –
Нормализация и дедупликация
SEO Spider нормализует URL-адреса при загрузке и устраняет дублирование во время сканирования. Допустим, у вас есть следующие 4 URL-адреса для загрузки, например –
SEO Spider автоматически определит, сколько уникальных URL-адресов нужно сканировать.
Для небольшого списка легко увидеть (для большинства специалистов по поисковой оптимизации), что эти 4 URL-адреса на самом деле являются только 2-мя уникальными URL-адресами, но с более крупными списками это может быть менее очевидным.
Страница SEO Spider дублируется, а URL-адрес фрагмента (с ‘#’) не рассматривается как отдельный уникальный URL-адрес, поэтому он нормализуется при загрузке.
Если эти URL-адреса загружены в SEO Spider, он сообщит, что нашел 4 URL-адреса – и нормализует их в диалоговом окне окна –
Однако при сканировании он будет сканировать только уникальные URL-адреса (в данном случае 2).
Хотя он просканировал только 2 уникальных URL из 4 загруженных, вы все равно можете экспортировать исходный загруженный список в том же порядке.
1) Scheduling
You can now to run automatically within the SEO Spider, as a one off, or at chosen intervals.
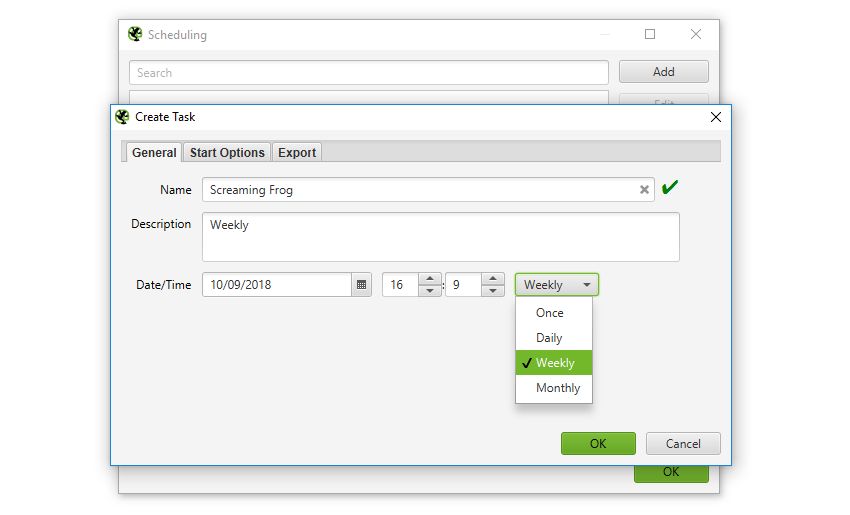
You’re able to pre-select the (spider, or list), saved , as well as APIs (, , , , ) to pull in any data for the scheduled crawl.
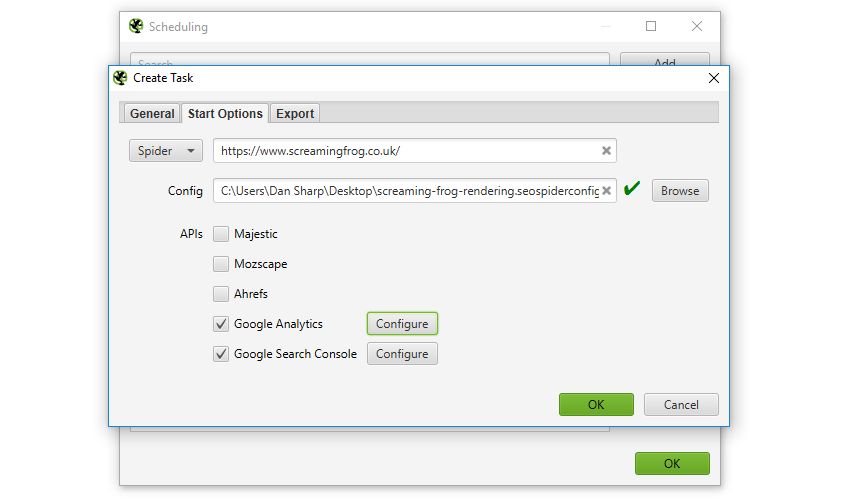
You can also automatically file and export any of the tabs, filters, , or XML Sitemaps to a chosen location.
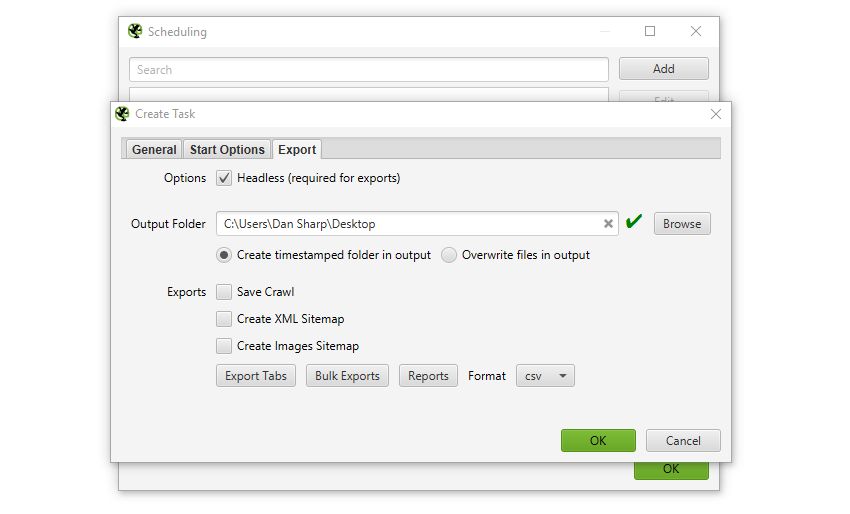
This should be super useful for anyone that runs regular crawls, has clients that only allow crawling at certain less-than-convenient ‘but, I’ll be in bed!’ off-peak times, uses crawl data for their own automatic reporting, or have a developer that needs a broken links report sent to them every Tuesday by 7 am.
The keen-eyed among you may have noticed that the SEO Spider will run in headless mode (meaning without an interface) when scheduled to export data – which leads us to our next point.
Small Update – Version 4.1 Released 16th July 2015
We have just released a small update to version 4.1 of the Screaming Frog SEO Spider. There’s a new ‘GA Not Matched’ report in this release, as well as some bug fixes. This release includes the following –
GA Not Matched Report
We have released a new ‘GA Not Matched’ report, which you can find under the ‘reports’ menu in the top level navigation.
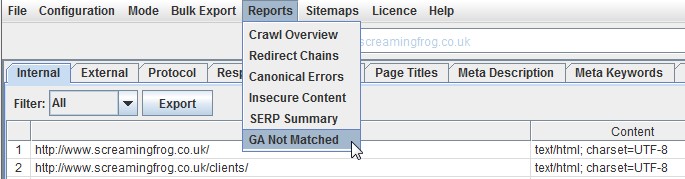
Data within this report is only available when you’ve connected to the Google Analytics API and collected data for a crawl. It essentially provides a list of all URLs collected from the GA API, that were not matched against the URLs discovered within the crawl.
This report can include anything that GA returns, such as pages in a shopping cart, or logged in areas. Hence, often the most useful data for SEOs is returned by querying the path dimension and ‘organic traffic’ segment. This can then help identify –
- Orphan Pages – These are pages that are not linked to internally on the website, but do exist. These might just be old pages, those missed in an old site migration or pages just found externally (via external links, or referring sites). This report allows you to browse through the list and see which are relevant and potentially upload via .
- Errors – The report can include 404 errors, which sometimes include the referring website within the URL as well (you will need the ‘all traffic’ segment for these). This can be useful for chasing up websites to correct external links, or just 301 redirecting the URL which errors, to the correct page! This report can also include URLs which might be canonicalised or blocked by robots.txt, but are actually still indexed and delivering some traffic.
- GA URL Matching Problems – If data isn’t matching against URLs in a crawl, you can check to see what URLs are being returned via the GA API. This might highlight any issues with the particular Google Analytics view, such as filters on URLs, such as ‘extended URL’ hacks etc. For the SEO Spider to return data against URLs in the crawl, the URLs need to match up. So changing to a ‘raw’ GA view, which hasn’t been touched in anyway, might help.
Other bug fixes in this release include the following –
- Fixed a couple of crashes in the custom extraction feature.
- Fixed an issue where GA requests weren’t going through the configured proxy.
- Fixed a bug with URL length, which was being incorrectly reported.
- We changed the GA range to be 30 days back from yesterday to match GA by default.
I believe that’s everything for now and please do let us know if you have any problems or spot any bugs via our support. Thanks again to everyone for all their support and feedback as usual.
Now go and !
6) Post Crawl Analysis
The SEO Spider is now able to perform further analysis at the end of a crawl (or when it’s stopped) for more data and insight. This includes the new ‘Link Score’ metric and a number of other new filters that have been introduced.
can be automatically performed at the end of a crawl, or it can be run manually by the user. This can be viewed under ‘Crawl Analysis > Configure’ and the crawl analysis can be started by selecting ‘Crawl Analysis > Start’. When the analysis is running, the SEO Spider can continue to be used as normal.
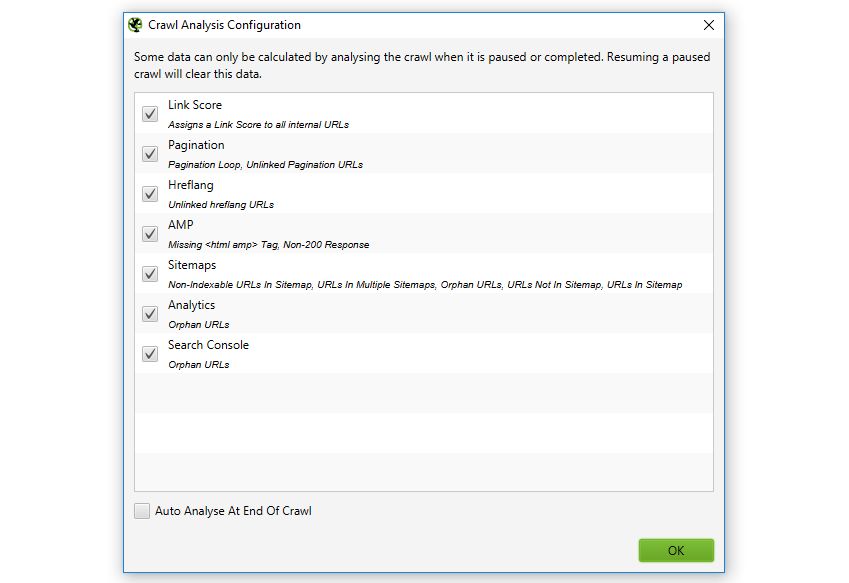
When the crawl analysis has finished, the empty filters which are marked with ‘Crawl Analysis Required’, will be populated with data.
Most of these items were already available via , but this new feature brings them into the interface to make them more visible, too.
Small Update – Version 13.1 Released 15th July 2020
We have just released a small update to version 13.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- We’ve introduced two new reports for Google Rich Result features discovered in a crawl under ‘Reports > Structured Data’. There’s a summary of features and number of URLs they affect, and a granular export of every rich result feature detected.
- Fix issue preventing start-up running on macOS Big Sur Beta
- Fix issue with users unable to open .dmg on macOS Sierra (10.12).
- Fix issue with Windows users not being able to run when they have Java 8 installed.
- Fix TLS handshake issue connecting to some GoDaddy websites using Windows.
- Fix crash in PSI.
- Fix crash exporting the Overview Report.
- Fix scaling issues on Windows using multiple monitors, different scaling factors etc.
- Fix encoding issues around URLs with Arabic text.
- Fix issue when amending the ‘Content Area’.
- Fix several crashes running Spelling & Grammar.
- Fix several issues around custom extraction and XPaths.
- Fix sitemap export display issue using Turkish locale.
Small Update – Version 14.2 Released 16th February 2021
We have just released a small update to version 14.2 of the SEO Spider. This release includes a couple of cool new features, alongside lots of small bug fixes.
Core Web Vitals Assessment
We’ve introduced a ‘Core Web Vitals Assessment’ column in the PageSpeed tab with a ‘Pass’ or ‘Fail’ using field data collected via the PageSpeed Insights API for Largest Contentful Paint, First Input Delay and Cumulative Layout Shift.
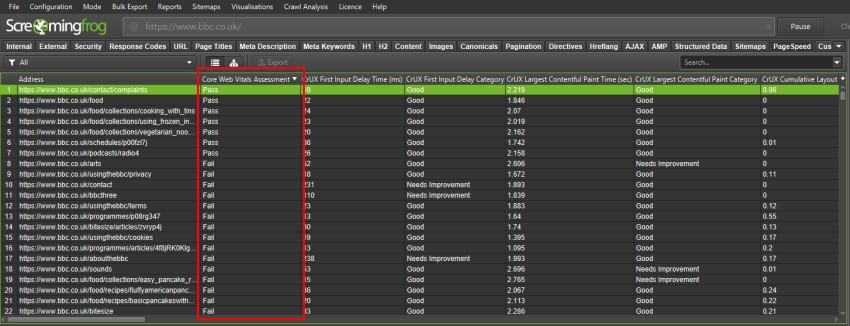
For a page to ‘pass’ the Core Web Vital Assessment it must be considered ‘Good’ in all three metrics, based upon Google’s various thresholds for each. If there’s no data for the URL, then this will be left blank.
This should help identify problematic sections and URLs more efficiently. Please see our tutorial on How To Audit Core Web Vitals.
Broken Bookmarks (or ‘Jump Links’)
Bookmarks are a useful way to link users to a specific part of a webpage using named anchors on a link, also referred to as ‘jump links’ or ‘anchor links’. However, they frequently become broken over time – even for Googlers.
To help with this problem, there’s now a check in the SEO Spider which crawls URLs with fragment identifiers and verifies that an accurate ID exists within the HTML of the page for the bookmark.
You can enable ‘Crawl Fragment Identifiers’ under ‘Config > Spider > Advanced’, and then view any broken bookmarks under the URL tab and new ‘Broken Bookmark’ filter.
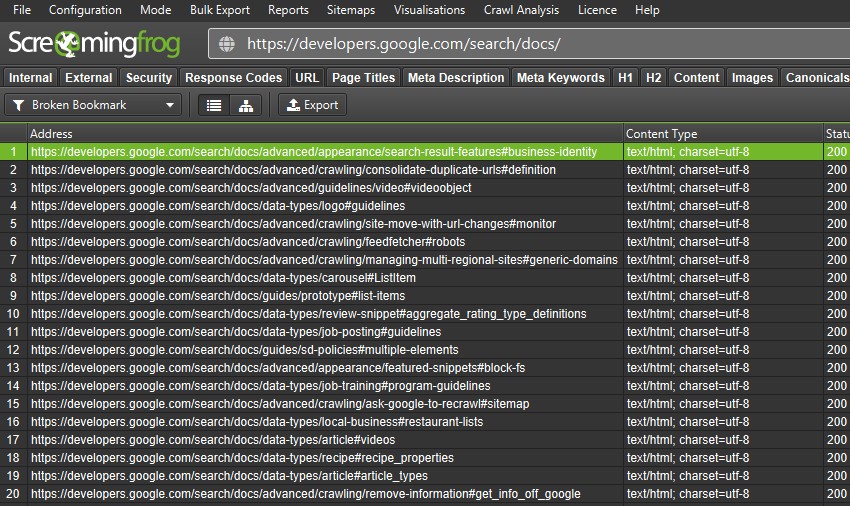
You can view the source pages these are on by using the ‘inlinks’ tab, and export in bulk via a right click ‘Export > Inlinks’. Please see our tutorial on How To Find Broken Bookmark & Jump Links.
14.2 also includes the following smaller updates and bug fixes.
- Improve labeling in all HTTP headers report.
- Update some column names to make more consistent – For those that have scripts that work from column naming, these include – Using capital case for ‘Length’ in h1 and h2 columns, and pluralising ‘Meta Keywords’ columns from singular to match the tab.
- Update link score graph calculations to exclude self referencing links via canoncials and redirects.
- Make srcset attributes parsing more robust.
- Update misleading message in visualisations around respecting canonicals.
- Treat HTTP response headers as case insensitive.
- Relax Job Posting value property type checking.
- Fix issue where right click ‘Export > Inlinks’ sometimes doesn’t export all the links.
- Fix freeze on M1 mac during crawl.
- Fix issue with Burmese text not displayed correctly.
- Fix issue where Hebrew text can’t be input into text fields.
- Fix issue with ‘Visualisations > Inlink Achor Text Word Cloud’ opening two windows.
- Fix issue with Forms Based Auth unlock icon not displaying.
- Fix issue with Forms Based Auth failing for sites with invalid certificates.
- Fix issue with Overview Report showing incorrect site URL in some situations.
- Fix issue with Chromium asking for webcam access.
- Fix issue on macOS where launching via a .seospider/.dbseospider file doesn’t always load the file.
- Fix issue with Image Preview incorrectly showing 404.
- Fix issue with PSI CrUX data being duplicated in Origin.
- Fix various crashes in JavaScript crawling.
- Fix crash parsing some formats of HTML.
- Fix crash when re-spidering.
- Fix crash performing JavaScript crawl with empty user agent.
- Fix crash selecting URL in master view when all tabs in details view are disabled/hidden.
- Fix crash in JavaScript crawling when web server sends invalid UTF-8 characters.
- Fix crash in Overview tab.
Small Update – Version 3.3 Released 23rd March 2015
We have just released another small update to version 3.3 of the Screaming Frog SEO Spider. Similar to the above, this is just a small release with a few updates, which include –
- Fixed a relative link bug for URLs.
- Updated the right click options for ‘Show Other Domains On This IP’, ‘Check Index > Yahoo’ and OSE to a new address.
- CSV files now don’t include a BOM (Byte Order Mark). This was needed before we had excel export integration. It causes problems with some tools parsing the CSV files, so has been removed, as suggested by Kevin Ellen.
- Fixed a couple of crashes when using the right click option.
- Fixed a bug where images only linked to via an HREF were not included in a sitemap.
- Fixed a bug effecting users of 8u31 & JDK 7u75 and above trying to connect to SSLv3 web servers.
- Fixed a bug with handling of mixed encoded links.
You can download the SEO Spider 3.3 now.
Thanks to everyone for all their comments on the latest version and feeback as always.
Understanding Bot Behaviour with the Log File Analyzer
An often-overlooked exercise, nothing gives us quite the insight into how bots are interacting through a site than directly from the server logs. The trouble is, these files can be messy and hard to analyse on their own, which is where our very own Log File Analyzer (LFA) comes into play, (they didn’t force me to add this one in, promise!).
I’ll leave @ScreamingFrog to go into all the gritty details on why this tool is so useful, but my personal favourite aspect is the ‘Import URL data’ tab on the far right. This little gem will effectively match any spreadsheet containing URL information with the bot data on those URLs.

So, you can run a crawl in the Spider while connected to GA, GSC and a backlink app of your choice, pulling the respective data from each URL alongside the original crawl information. Then, export this into a spreadsheet before importing into the LFA to get a report combining metadata, session data, backlink data and bot data all in one comprehensive summary, aka the holy quadrilogy of technical SEO statistics.
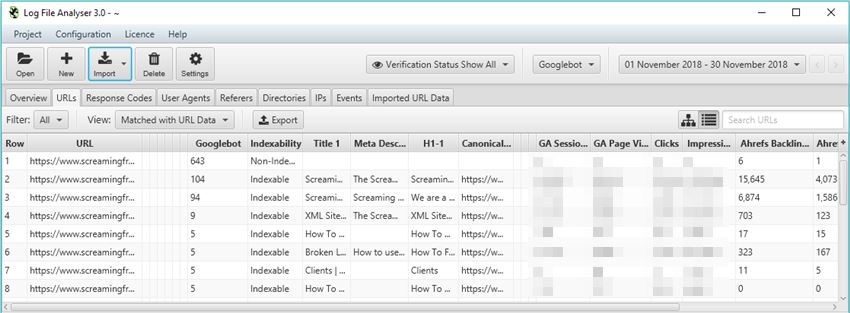
While the LFA is a paid tool, there’s a free version if you want to give it a go.
Crawl Reporting in Google Data Studio
One of my favourite reports from the Spider is the simple but useful ‘Crawl Overview’ export (Reports > Crawl Overview), and if you mix this with the scheduling feature, you’re able to create a simple crawl report every day, week, month or year. This allows you to monitor and for any drastic changes to the domain and alerting to anything which might be cause for concern between crawls.
However, in its native form it’s not the easiest to compare between dates, which is where Google Sheets & Data Studio can come in to lend a hand. After a bit of setup, you can easily copy over the crawl overview into your master G-Sheet each time your scheduled crawl completes, then Data Studio will automatically update, letting you spend more time analysing changes and less time searching for them.
This will require some fiddling to set up; however, at the end of this section I’ve included links to an example G-Sheet and Data Studio report that you’re welcome to copy. Essentially, you need a G-Sheet with date entries in one column and unique headings from the crawl overview report (or another) in the remaining columns:

Once that’s sorted, take your crawl overview report and copy out all the data in the ‘Number of URI’ column (column B), being sure to copy from the ‘Total URI Encountered’ until the end of the column.
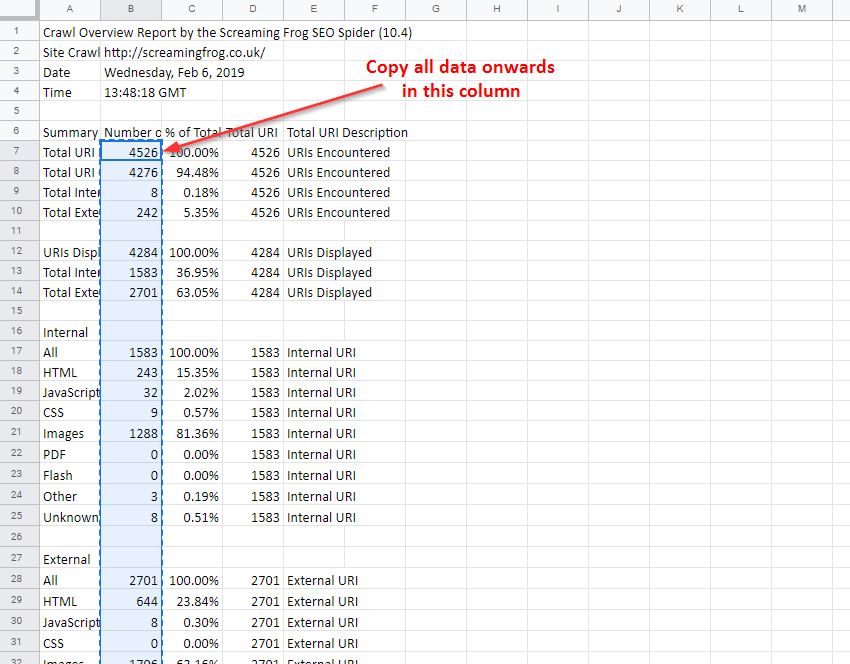
Open your master G-Sheet and create a new date entry in column A (add this in a format of YYYYMMDD). Then in the adjacent cell, Right-click > ‘Paste special’ > ‘Paste transposed’ (Data Studio prefers this to long-form data):
![]()
If done correctly with several entries of data, you should have something like this:

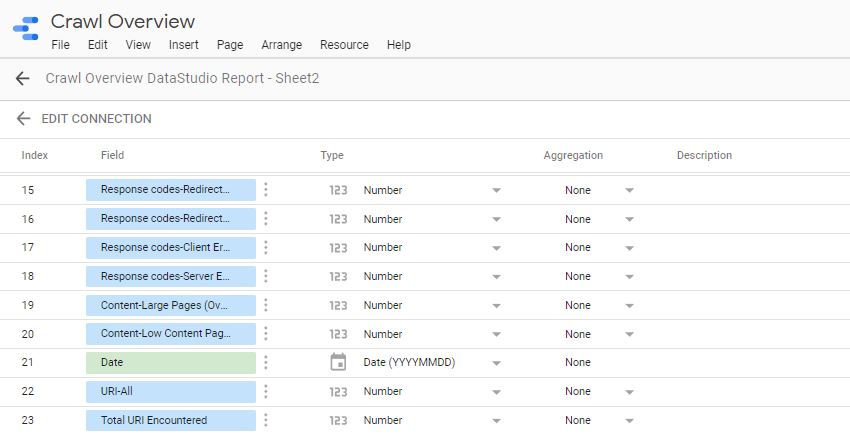
Once the data is in a G-Sheet, uploading this to Data Studio is simple, just create a new report > add data source > connect to G-Sheets > > and make sure all the heading entries are set as a metric (blue) while the date is set as a dimension (green), like this:
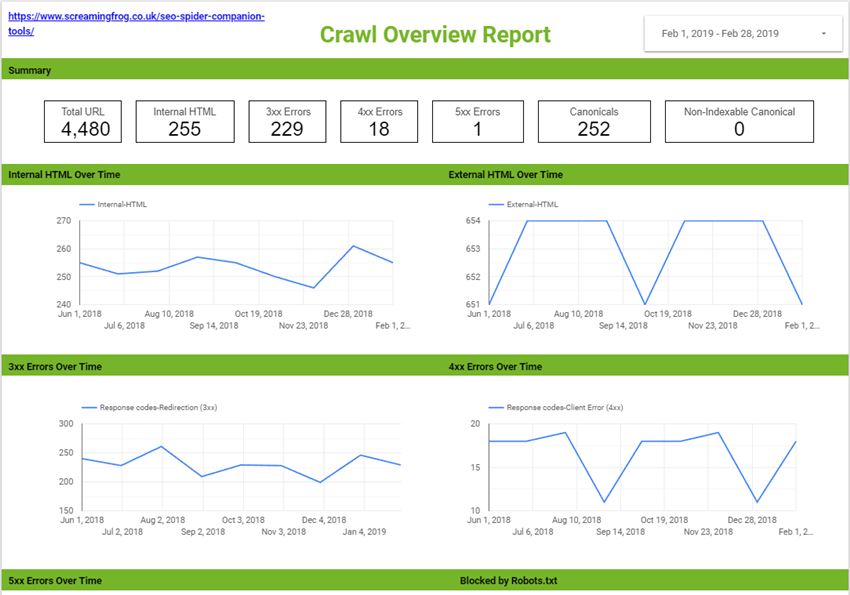
You can then build out a report to display your crawl data in whatever format you like. This can include scorecards and tables for individual time periods, or trend graphs to compare crawl stats over the date range provided, (you’re very own Search Console Coverage report).
Here’s an overview report I quickly put together as an example. You can obviously do something much more comprehensive than this should you wish, or perhaps take this concept and combine it with even more reports and exports from the Spider.
If you’d like a copy of both my G-Sheet and Data Studio report, feel free to take them from here:
Master Crawl Overview G-Sheet: https://docs.google.com/spreadsheets/d/1FnfN8VxlWrCYuo2gcSj0qJoOSbIfj7bT9ZJgr2pQcs4/edit?usp=sharing
Crawl Overview Data Studio Report: https://datastudio.google.com/open/1Luv7dBnkqyRj11vLEb9lwI8LfAd0b9Bm
Note: if you take a copy some of the dimension formats may change within DataStudio (breaking the graphs), so it’s worth checking the date dimension is still set to ‘Date (YYYMMDD)’
Small Update – Version 12.4 Released 18th December 2019
We have just released a small update to version 12.4 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Remove checks from deprecated Google Features.
- Respect sort and search when exporting.
- Improved config selection in scheduler UI.
- Allow users without crontab entries to schedule crawls on Ubuntu.
- Speed up table scrolling when using PSI.
- Fix crash when sorting, searching and clearing table views.
- Fix crash editing scheduled tasks.
- Fix crash when dragging and dropping.
- Fix crash editing internal URL config.
- Fix crash editing speed config.
- Fix crash when editing custom extractions then resuming a paused crawl.
- Fix freeze when performing crawl analysis.
- Fix issues with GA properties with + signs not parsed on a Mac.
- Fix crash when invalid path is used for database directory.
- Fix crash when plugging in and out multiple screens on macOS.
- Fix issue with exporting inlinks being empty sometimes.
- Fix issue on Windows with not being able to export the current crawl.
- Fix crash on macOS caused by using accessibility features.
- Fix issue where scroll bar stops working in the main table views.
- Fix crash exporting .xlsx files.
- Fix issue with word cloud using title tags from svg tags.
5) Агрегированная структура сайта
SEO Spider теперь отображает количество URL-адресов, обнаруженных в каждом каталоге, в дереве каталогов (к которому вы можете получить доступ через значок дерева рядом с «Экспорт» на верхних вкладках).
Это помогает лучше понять размер и архитектуру веб-сайта, и некоторые пользователи считают его более логичным в использовании, чем традиционное представление списка.
Наряду с этим обновлением команда разработчиков улучшила правую вкладку «Структура сайта», чтобы отобразить агрегированное представление веб-сайта в виде дерева каталогов. Это помогает быстро визуализировать структуру веб-сайта и с первого взгляда определять, где возникают проблемы, например, индексируемость различных путей.
Если вы нашли области сайта с неиндексируемыми URL-адресами, вы можете переключить «вид», чтобы проанализировать «статус индексируемости» этих различных сегментов пути, чтобы увидеть причины, по которым они считаются неиндексируемыми.
Вы также можете переключить представление на глубину сканирования по каталогам, чтобы помочь выявить любые проблемы с внутренними ссылками на разделы сайта и многое другое.
Этот более широкий агрегированный вид веб-сайта должен помочь вам визуализировать архитектуру и принимать более обоснованные решения для различных разделов и сегментов.
Other Updates
Version 14.0 also includes a number of smaller updates and bug fixes, outlined below.
- There’s now a new filter for ‘Missing Alt Attribute’ under the ‘Images’ tab. Previously missing and empty alt attributes would appear under the singular ‘Missing Alt Text’ filter. However, it can be useful to separate these, as decorative images should have empty alt text (alt=””), rather than leaving out the alt attribute which can cause issues in screen readers. Please see our How To Find Missing Image Alt Text & Attributes tutorial.
- Headless Chrome used in JavaScript rendering has been updated to keep up with evergreen Googlebot.
- ‘Accept Cookies’ has been adjusted to ‘‘, with three options – Session Only, Persistent and Do Not Store. The default is ‘Session Only’, which mimics Googlebot’s stateless behaviour.
- The ‘URL’ tab has new filters available around common issues including Multiple Slashes (//), Repetitive Path, Contains Space and URLs that might be part of an Internal Search.
- The ‘‘ tab now has a filter for ‘Missing Secure Referrer-Policy Header’.
- There’s now a ‘HTTP Version’ column in the Internal and Security tabs, which shows which version the crawl was completed under. This is in preparation for supporting HTTP/2 crawling inline with Googlebot.
- You’re now able to right click and ‘close’ or drag and move the order of lower window tabs, in a similar way to the top tabs.
- Non-Indexable URLs are now not included in the ‘URLs not in Sitemap’ filter, as we presume they are non-indexable correctly and therefore shouldn’t be flagged. Please see our tutorial on ‘How To Audit XML Sitemaps‘ for more.
- Google rich result feature validation has been updated inline with the ever-changing documentation.
- The ‘Google Rich Result Feature Summary’ report available via ‘‘ in the top-level menu, has been updated to include a ‘% eligible’ for rich results, based upon errors discovered. This report also includes the total and unique number of errors and warnings discovered for each Rich Result Feature as an overview.
That’s everything for now, and we’ve already started work on features for version 15. If you experience any issues, please let us know via support and we’ll help.
Thank you to everyone for all their feature requests, feedback, and continued support.
Now, go and download version 14.0 of the Screaming Frog SEO Spider and let us know what you think!
Troubleshooting
If set up correctly, this process should be seamless but occasionally Google might catch wind of what you’re up too and come down to stop your fun with an annoying anti-bot captcha test.
If this happens just pause your crawl, load up a PSI page in a browser to solve the captcha, then jump back in the tool highlight the URLs that did not extract any data right click > Re-Spider.

If this continues the likelihood is you have your crawl speed set too high, if you lower it down a bit in the options mentioned above it should put you back on track.
I’ve also noticed a number of comments reporting the PSI page not properly rendering and nothing being extracted. If this happens it might be worth a clear to the default config (File > Configuration > Clear to default). Next, make sure the user-agent is set to ScreamingFrog. Finally, ensure you have the following configuration options ticked (Configuration > Spider):
- Check Images
- Check CSS
- Check JavaScript
- Check SWF
- Check External Links
If for any reason, the page is rendering correctly but some scores weren’t extracted, double check the Xpaths have been entered correctly and the dropdown is changed to ‘Extract Text’. Secondly, it’s worth checking PSI actually has that data by loading it in a browser — much of the real-world data is only available on high-volume pages.
10) Improved Redirect & Canonical Chain Reports
The SEO Spider now reports on canonical chains and ‘mixed chains’, which can be found in the renamed ‘Redirect & Canonical Chains’ report.
For example, the SEO Spider now has the ability to report on mixed chain scenarios such as, redirect to a URL which is canonicalised to another URL, which has a meta refresh to another URL, which then JavaScript redirects back to the start URL. It will identify this entire chain, and report on it.
The updated report has also been updated to have fixed position columns for the start URL, and final URL in the chain, and reports on the indexability and indexability status of the final URL to make auditing more efficient to see if a redirect chain ends up at a ‘noindex’ or ‘error’ page etc. The full hops in the chain are still reported as previously, but in varying columns afterwards.
This means auditing redirects is significantly more efficient, as you can quickly identify the start and end URLs, and discover the chain type, the number of redirects and the indexability of the final target URL immediately. There’s also flags for chains where there is a loop, or have a temporary redirect somewhere in the chain.
There simply isn’t a better tool anywhere for auditing redirects at scale, and while a feature like visualisations might receive all the hype, this is significantly more useful for technical SEOs in the trenches every single day. Please read our updated guide on auditing redirects in a site migration.
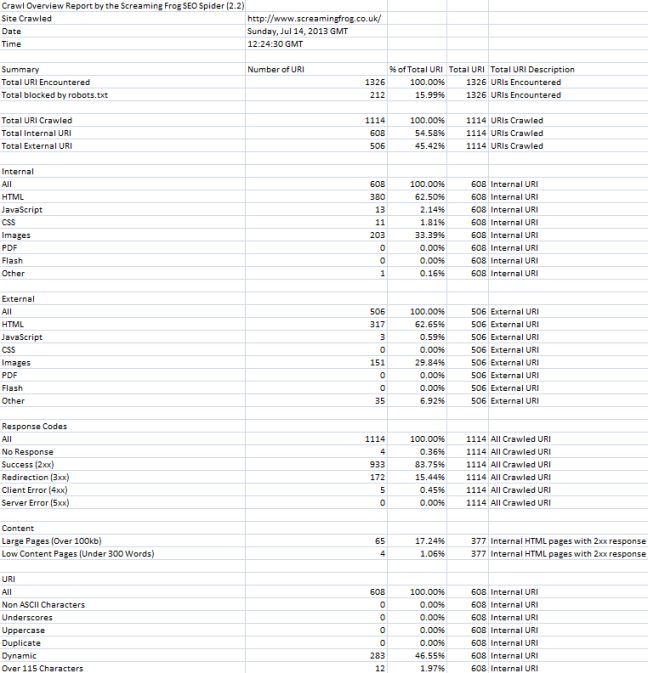
Crawl Overview Report
Under the new ‘reports’ menu discussed above, we have included a little ‘crawl overview report’. This does exactly what it says on the tin and provides an overview of the crawl, including total number of URLs encountered in the crawl, the total actually crawled, the content types, response codes etc with proportions. This will hopefully provide another quick easy way to analyse overall site health at a glance. Here’s a third of what the report looks like –
We have also changed the max page title length to 65 characters (although it seems now to be based on pixel image width), added a few more preset mobile user agents, fixed some bugs (such as large sitemaps being created over the 10Mb limit) and made other smaller tweaks along the way.
As always, we love any feedback and thank you again for all your support. Please do update your to try out all the new features.